The end of the “best open LLM”
🌈 Abstract
The article discusses the evolving landscape of open large language models (LLMs), highlighting the emergence of new models that challenge the notion of a singular "best open LLM." It examines the compute versus performance tradeoff of various open LLMs, including Llama, Mixtral, DBRX, and others, and suggests that the most important models will represent improvements in capability density rather than just size.
🙋 Q&A
[01] The end of the "best open LLM"
1. What are the key points made about the concept of a "best open LLM"?
- The author has previously declared three models (Llama 2, Mixtral, and DBRX) as the "best open LLM" at different times, as they represented substantial jumps in performance per parameter.
- However, the landscape has shifted with the release of new models like Cohere's Command R+ and Mistral's 8x22B, which have surpassed the performance of previous "best" models.
- The author argues that there is no longer a clear "best open LLM" and that the focus should be on the weighted performance per parameter and training token count.
2. What are the key factors that have contributed to the shift in the "best open LLM" landscape?
- The release of models like Cohere's Command R+ and Mistral's 8x22B, which have outperformed previous "best" models.
- The increasing availability of larger and more capable open LLMs, such as DBRX and Mistral 8x22B, which are difficult for most of the open community to work with due to their size and compute requirements.
- The author's own bias in aligning the narrative around open models, which may have led to the underadoption of models like Yi 34B and Qwen 1.5 72B.
[02] Compute efficient open LLMs
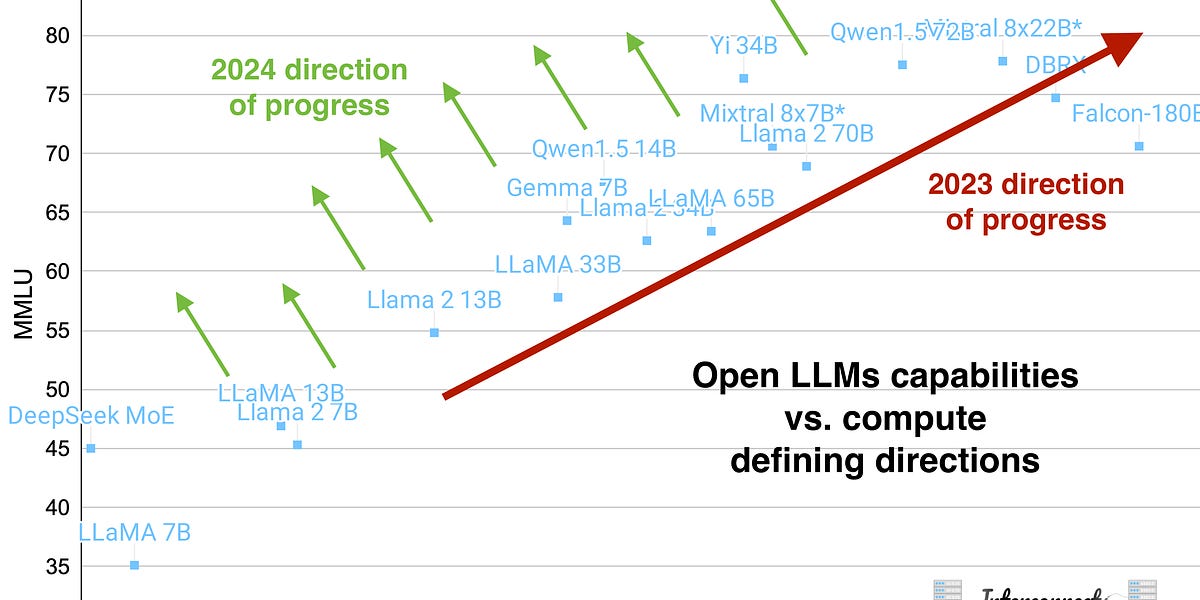
1. How does the author analyze the relationship between compute and performance for open LLMs?
- The author creates a model to showcase the compute versus MMLU (Massive Multitask Language Understanding) tradeoff for various open LLMs.
- The analysis shows that most of the gains in open LLMs have come from simply throwing more compute at the problem, with a clear correlation between increased compute and improved performance.
- The author highlights that the most important models will represent improvements in capability density rather than just size.
2. What insights does the author provide about the training token counts of open LLMs compared to industry models?
- The author notes that most open LLMs are significantly undertrained compared to industry models, with only DBRX confirmed to be trained on a large number of tokens (12 trillion).
- Many open models are in the 2-3 trillion token range, which represents a significant difference from industry models that are likely trained on all of their effective tokens.
- The author suggests that it is often easier to improve the performance of open LLMs by training them for longer, if the data is available.
3. How does the author expect the landscape of open LLMs to evolve going forward?
- The author is excited to see the performance of future Llama 2.5 or 3 models, as the Llama models were previously released into an open plain with little competition.
- The author expects Meta to try to fine-tune a model that scores well on the LMSYS ChatBotArena leaderboard, given the cultural weight of that evaluation and the relative failure of Llama 2 Chat's release.