Understanding the Knowledge Graph & RAG Opportunity
🌈 Abstract
The article discusses the accelerating enterprise adoption of Generative AI, with a focus on the role of Retrieval-Augmented Generation (RAG) and knowledge graphs in enabling more reliable and deterministic AI systems. It covers the following key points:
🙋 Q&A
[01] Enterprise Adoption of Generative AI
1. What are the key obstacles preventing enterprises from moving LLM use cases into production?
- Model output accuracy and hallucinations are the two main obstacles preventing enterprises from moving LLM use cases into production.
- This has led to a bifurcation of adoption cycles between internal and external use cases, with lower hallucination tolerance for external use cases.
2. How are enterprises becoming more sophisticated in deploying large models?
- Enterprises are customizing LLMs through fine-tuning and RAG, which are not mutually exclusive approaches.
- There is increasing consensus that out-of-the-box LLMs need to be augmented, with compound systems comprising multiple components rather than just monolithic models.
[02] The RAG Stack
1. What are the key components of a simple RAG stack?
- Documents are turned into embeddings, which are stored in a vector database.
- When a query is asked, the query is turned into a set of mathematical representations, which are compared against the vectors in the database to retrieve the most semantically similar information.
2. How does a complex RAG system differ from a simple RAG stack?
- Complex RAG systems employ multi-hop retrieval, extracting and combining information from multiple sources to answer complex questions that require linking diverse pieces of information.
3. What is the role of knowledge graphs in the RAG stack?
- Knowledge graphs help realize the full potential of RAG by enhancing baseline RAG with additional context that can be specific to a company or domain.
- Knowledge graphs can be used as a data store to retrieve information from, or as a data store of the semantic structure to retrieve vector chunks from.
[03] The Importance of Knowledge Graphs
1. How are enterprises using knowledge graphs to improve the accuracy and reliability of their RAG systems?
- Knowledge graphs help make LLMs more deterministic by providing structured data and relationships, which is essential for critical enterprise use cases.
- Examples are provided of how ServiceNow and Deutsche Telekom are using knowledge graphs to improve the accuracy and reliability of their AI-powered applications.
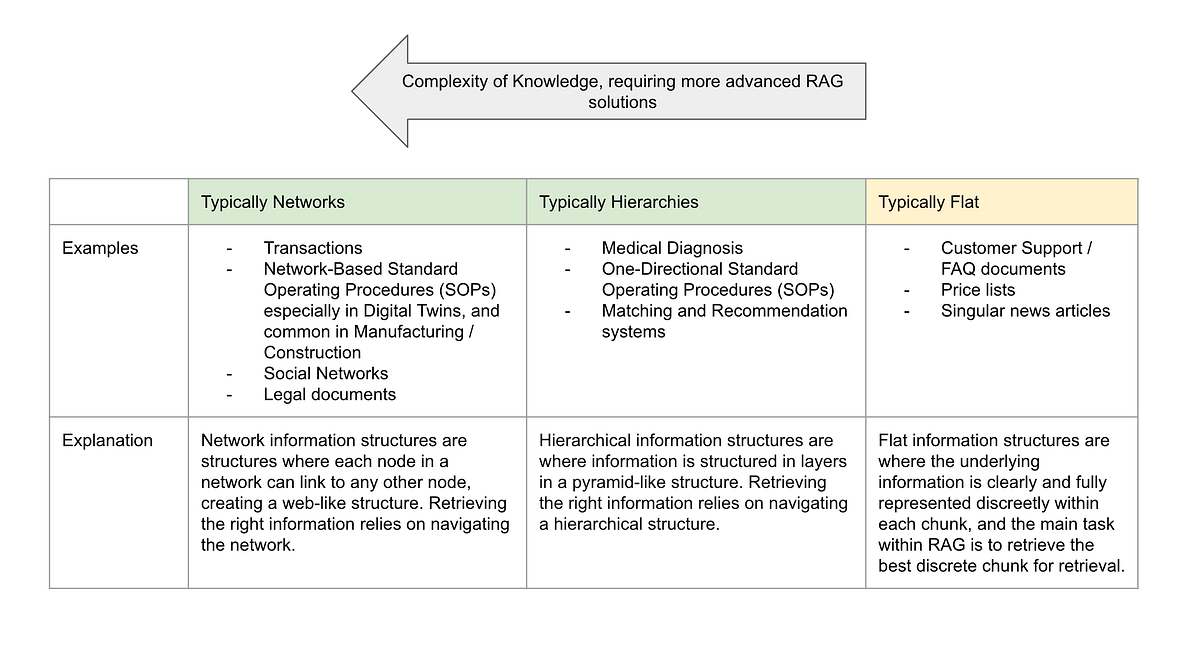
2. What are the key scenarios where knowledge graphs are more or less relevant for RAG systems?
- Knowledge graphs are more relevant for scenarios involving conceptual aggregation, conceptual alignment, hierarchical retrieval, hierarchical recommendation, and personalization/memory.
- Knowledge graphs are less relevant for scenarios where the number of errors is low, for consumer-facing chatbots, for non-hierarchical/non-semantically similar answer sets, and for time-series information.
[04] The Future of RAG and Knowledge Graphs
1. How are small graphs and multi-agent systems shaping the future of RAG?
- Instead of creating a large representation of knowledge, LLMs and workflow tooling can help create very specific knowledge representations in the form of small, independently managed sub-graphs tied to specific agents.
- This allows for more targeted and deterministic information retrieval, with reduced risk of hallucinations.
2. How are knowledge graphs becoming a strategic moat for domain-specific enterprises?
- Companies are increasingly using knowledge graphs to represent their domain-specific expertise and data, which can serve as a long-term moat in the AI age.
- This structured representation of proprietary data can be used as a foundational building block for both RAG and fine-tuning domain-specific models.