GPT-3.5 Turbo FINALLY Has A Successor
🌈 Abstract
The article discusses the recent advancements in large language models (LLMs) and their impact on the pricing and accessibility of AI-powered applications. It focuses on the release of GPT-4o Mini by OpenAI, which significantly reduces the cost of using LLMs compared to previous models.
🙋 Q&A
[01] Pricing and Cost Reductions of LLMs
1. What are the key points about the pricing and cost reductions of LLMs discussed in the article?
- The article mentions that the cost of LLMs has dropped significantly, with GPT-3.5 Turbo costing $20 per million tokens when it was released, but the new Claude 3.0 Haiku model costing only $0.25 per million input tokens and $1.25 per million output tokens, a 50x drop in prices.
- The author speculated that LLM costs would continue to drop, and this prediction was validated when OpenAI announced the GPT-4o Mini model, which halves the price of LLMs compared to the previous cheapest models.
- The article notes that the GPT-4o Mini model costs 15 cents per million input tokens and 60 cents per million output tokens, more than halving the prices of the previous cheapest models.
2. How does the pricing of GPT-4o Mini compare to other LLM models?
- The article discusses the pricing tiers of LLMs, with high-cost "money-is-no-object" models like Claude 3.5 Sonnet and GPT-4o, and budget LLMs like Claude 3.0 Haiku, Gemini 1.5 Flash, and now GPT-4o Mini.
- The author notes that the competition has primarily been in the budget LLM area, as budget models are cheaper to train and develop, and the results are not significantly different from the expensive versions.
- The article suggests that OpenAI had been ignoring the budget LLM market, but the release of GPT-4o Mini shows they are now addressing this segment.
[02] Performance and Capabilities of GPT-4o Mini
1. How does the performance of GPT-4o Mini compare to other LLM models?
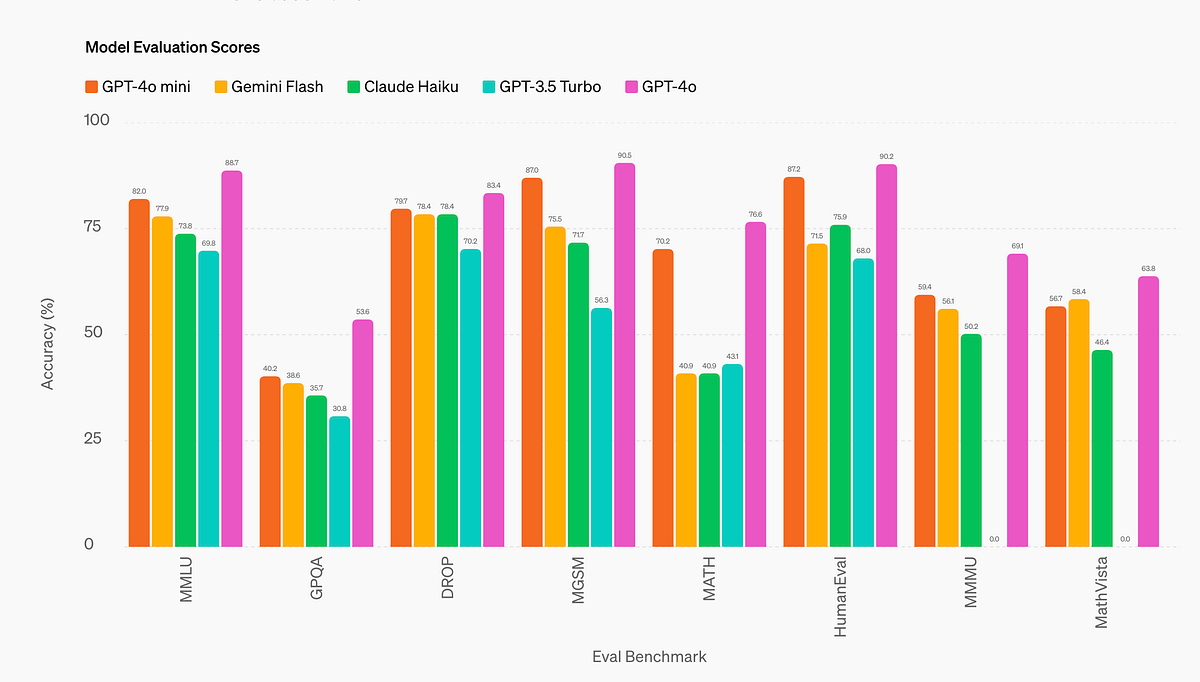
- The article discusses the performance of GPT-4o Mini, noting that while the author is skeptical of the performance graphs presented by OpenAI, they have no reason to believe the model will perform significantly worse than other models.
- The author compares GPT-4o Mini to the older GPT-3.5 Turbo model, stating that they prefer GPT-3.5 Turbo in some ways, but acknowledging that GPT-4o Mini appears to perform quite a bit better.
- The article mentions that OpenAI partnered with companies like Ramp and Superhuman to test GPT-4o Mini, and these partners found the model to perform significantly better than GPT-3.5 Turbo for tasks like extracting structured data and generating high-quality email responses.
2. What other improvements does the GPT-4o Mini model offer?
- The article notes that the GPT-4o Mini model uses a new tokenization algorithm that provides better performance for non-Latin-based languages, such as a 1.4x improvement for Chinese, 1.7x for Korean, and 2.0x for Arabic.
- However, the author acknowledges that this improvement may not be relevant for their own use case, as their queries are in English.
- The article also discusses the input and output token limits of the GPT-4o Mini model, noting that the maximum input tokens is 128k, which may be a limitation compared to the 1 million token context length of the Gemini 1.5 Flash model.
[03] Implications and Future Outlook
1. What are the implications of the release of GPT-4o Mini?
- The article suggests that the release of GPT-4o Mini shows that OpenAI is serious about budget LLM models, which the author sees as both a positive and a potential concern for OpenAI's non-profit status.
- The author acknowledges that the significant cost reductions in LLMs are good for developers, as it allows them to access better models at a lower cost.
- The article speculates on the future of LLMs, suggesting that the 99% reduction in cost per token since the introduction of text-davinci-003 could lead to LLMs becoming "seamlessly integrated in every app and on every website."
2. What are the potential concerns or drawbacks discussed regarding the widespread integration of LLMs?
- The article notes that the author previously discussed how AI could make phones worse due to slower response times and increased memory footprints, and acknowledges that this is a potential concern as LLMs become more widely integrated.
- However, the author also recognizes that the trend towards more accessible and affordable LLMs is the direction the world is heading, "for better or for worse."
Shared by Daniel Chen ·
© 2024 NewMotor Inc.