Can AI Scaling Continue Through 2030?
🌈 Abstract
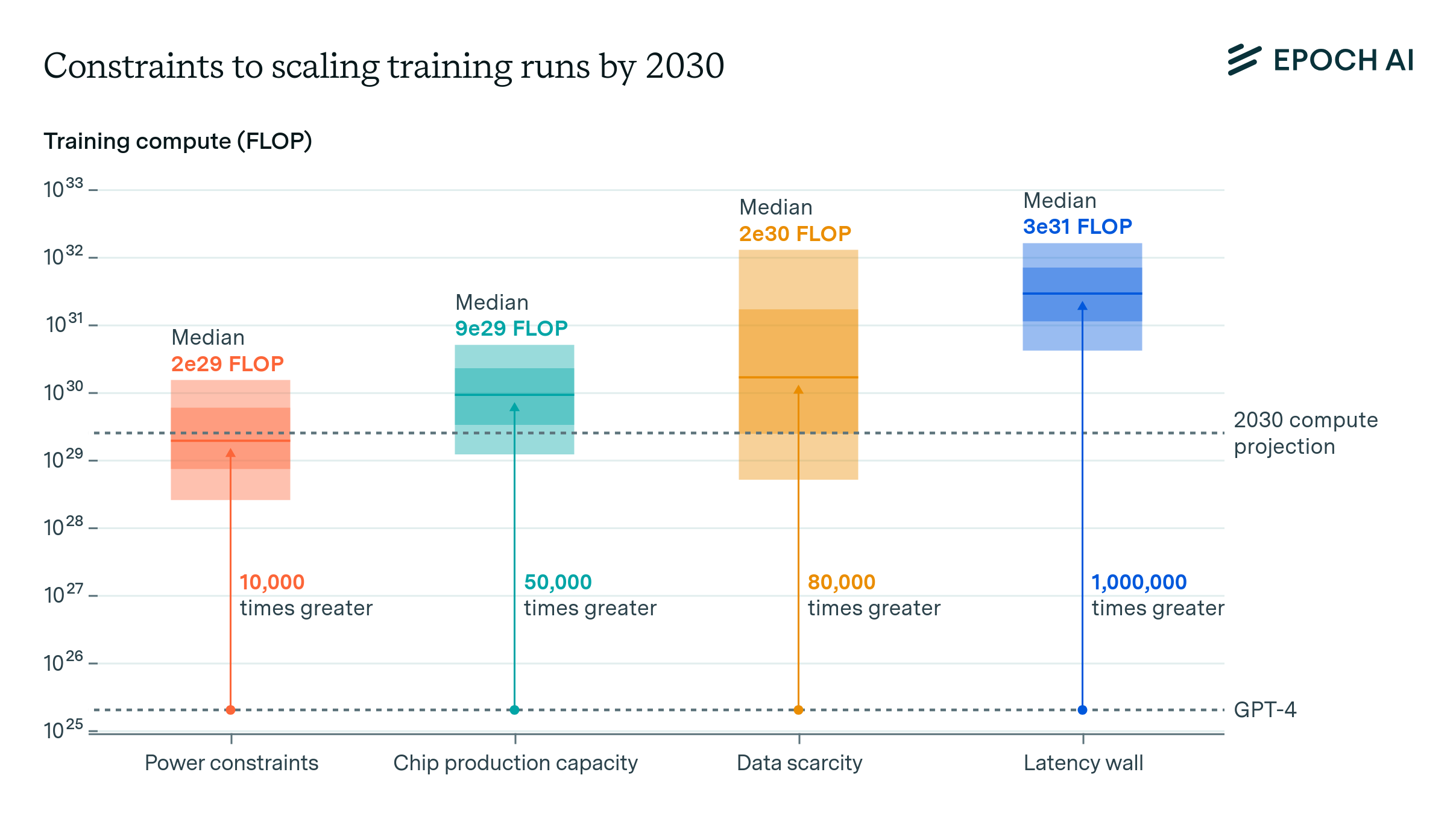
The article examines the technical feasibility of continuing the rapid pace of AI training scaling, which has been approximately 4x per year, through 2030. It analyzes four key factors that might constrain scaling: power availability, chip manufacturing capacity, data scarcity, and the "latency wall". The analysis incorporates the expansion of production capabilities, investment, and technological advancements. The article finds that training runs of 2e29 FLOP will likely be feasible by the end of this decade, representing a significant increase in scale over current models, similar to the size difference between GPT-2 and GPT-4.
🙋 Q&A
[01] Power Constraints
1. What are the key findings regarding power constraints for large-scale AI training?
- Plans for data center campuses of 1 to 5 GW by 2030 could support training runs ranging from 1e28 to 3e29 FLOP.
- A geographically distributed training network across the US could likely accommodate 2 to 45 GW, supporting training runs from 2e28 to 2e30 FLOP.
- Beyond this, an actor willing to pay the costs of new power stations could access significantly more power, if planning 3 to 5 years in advance.
2. What are the potential challenges in rapidly expanding the power supply for AI training?
- Transmission line construction and grid interconnection processes can take a long time, creating uncertainty about the ability to scale up power supply significantly faster than historical growth rates.
- There are political and regulatory constraints that could block or delay the construction of new power plants and supporting infrastructure.
- Tensions exist between the goal of massive power growth for AI and commitments to transition to 100% carbon-free energy by 2035 and net-zero emissions.
[02] Chip Manufacturing Capacity
1. What are the key findings regarding chip manufacturing capacity for AI training?
- Expansion is currently constrained by advanced packaging and high-bandwidth memory production capacity.
- Given planned scale-ups by manufacturers and hardware efficiency improvements, there is likely to be enough capacity for 100M H100-equivalent GPUs to be dedicated to training, powering a 9e29 FLOP training run.
- However, this projection carries significant uncertainty, with estimates ranging from 20 million to 400 million H100 equivalents, corresponding to 1e29 to 5e30 FLOP.
2. What are the main constraints on expanding chip manufacturing capacity?
- The availability of advanced packaging capacity, particularly TSMC's Chip-on-wafer-on-Substrate (CoWoS) process, is a key near-term bottleneck.
- The production of high-bandwidth memory (HBM) chips is another significant constraint, with HBM capacity projected to grow at 45-60% annually.
- While wafer production capacity is not the primary limiting factor, the capital expenditure required to substantially expand leading-edge chip manufacturing capacity presents a challenge.
[03] Data Scarcity
1. What are the key findings regarding data scarcity for large-scale AI training?
- The indexed web contains about 500T words of unique text, projected to increase by 50% by 2030.
- Multimodal learning from image, video and audio data could moderately contribute to scaling, plausibly tripling the data available for training.
- After accounting for uncertainties, the effective dataset size is estimated to be 400 trillion to 20 quadrillion tokens by 2030, allowing for 6e28 to 2e32 FLOP training runs.
- Synthetic data generation from AI models could potentially increase the data supply substantially, but this approach is still uncertain.
2. What are the potential challenges and limitations around using multimodal and synthetic data for scaling?
- The utility of multimodal data for advancing reasoning capabilities may be limited, and there is uncertainty around the available stock of such data, its quality, and the efficiency of current tokenization methods.
- Synthetic data generation faces challenges such as the risk of model collapse and the potential for diminishing returns as more compute is invested in data generation.
[04] Latency Wall
1. What are the key findings regarding the latency wall as a constraint on AI scaling?
- The latency wall represents a fundamental speed limit imposed by the minimum time required for forward and backward passes during training.
- Increasing the batch size can amortize these latencies, but beyond a 'critical batch size', further increases yield diminishing returns.
- Estimates suggest that training runs up to 3e30 to 1e32 FLOP would be feasible with modern hardware, but surpassing this scale would require alternative network topologies, reduced communication latencies, or more aggressive batch size scaling.
2. What are some potential strategies to overcome the latency wall constraint?
- Adopting more complex network topologies, such as a mesh topology, to bypass the logarithmic scaling of inter-node latency.
- Increasing the size of server nodes to reduce the number of inter-node communications.
- Developing more efficient communication protocols, as demonstrated by Meta's NCCLX fork of the NVIDIA Collective Communications Library.
- Exploring ways to increase the critical batch size, such as by scaling it with the inverse of the reducible model loss.
[05] Overall Feasibility and Implications
1. What is the overall conclusion regarding the feasibility of large-scale AI training by 2030?
- Based on the analysis of the four key bottlenecks, training runs of up to 2e29 FLOP are likely to be feasible by the end of this decade.
- This would represent a roughly 10,000-fold scale-up relative to current models, similar to the size difference between GPT-2 and GPT-4.
2. What are the potential implications of achieving such large-scale AI training?
- It could attract investment over hundreds of billions of dollars, becoming the largest technological project in the history of humankind.
- The sheer scale of the models could translate into more performance and generality, potentially leading to advances in AI by the end of the decade as major as what has been experienced since the beginning of the decade.
- However, the article notes significant uncertainty around whether companies or governments will be willing to invest the required resources to pursue this level of scaling.