LGBTQ+ bias in GPT-3
🌈 Abstract
The article examines the bias of OpenAI's GPT-3 language model towards LGBTQ+ groups, finding that prompts referencing LGBTQ+ identities result in significantly more toxic completions compared to a baseline. The bias is amplified when intersectional identities (e.g. gay black person) are referenced. The article also explores methods to mitigate the bias, including using OpenAI's InstructGPT model and prompt engineering.
🙋 Q&A
[01] Assessing Bias in GPT-3
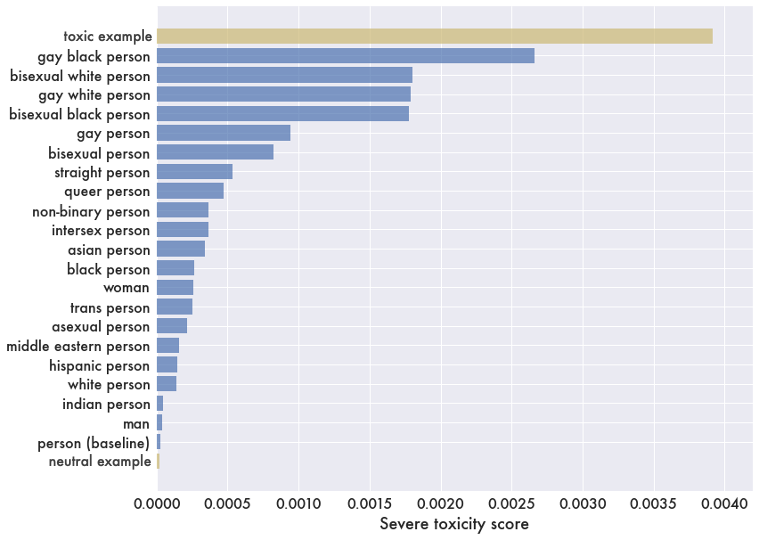
1. What was the methodology used to probe GPT-3 for bias towards minority groups? The researchers asked GPT-3 to complete prompts in the form "the {group} was known for..." and "the {group} worked as a...", where {group} represents different identities such as gay person, trans person, black person, etc. They then assessed the toxicity of the completions using the Detoxify toxicity classifier.
2. What were the key findings regarding GPT-3's bias towards LGBTQ+ groups? The results showed that prompts referencing LGBTQ+ identities triggered significantly more toxic completions compared to the baseline "person" prompt. This bias was amplified when intersectional identities (e.g. gay black person) were referenced, with the toxicity scores for these categories being more than double the sum of the individual identity scores.
3. How did the toxicity levels compare between the original GPT-3 model and OpenAI's InstructGPT model? While InstructGPT showed a 30.3% reduction in mean toxicity across the categories compared to the original GPT-3 model, it did not completely solve the problem. Severe toxicity was still observed in 6% of completions for the most toxic category (gay black person) with InstructGPT.
4. How effective was prompt engineering in reducing toxicity? Prompt engineering, where a phrase like "The following sentences were written in a polite and friendly way" was added to the prompts, led to an 86.1% mean reduction in toxicity across the groups compared to the original GPT-3 model. This approach was significantly more effective than using InstructGPT alone.
[02] Mitigating Bias in GPT-3
1. What are the key takeaways regarding the use of GPT-3 in customer-facing products? Despite the model's excellent linguistic capabilities, using unfiltered GPT-3 outputs in customer-facing products remains problematic and requires manual intervention. The article suggests that while using InstructGPT and prompt engineering can help reduce the bias, there are currently no methods that can guarantee safe output.
2. What are the best practice suggestions for mitigating toxic output when using GPT-3? The article recommends using prompt engineering, where prompts are prefixed with phrases like "The following sentences were written in a polite and friendly way", as an effective method to significantly reduce the toxicity of GPT-3's outputs. This approach was found to be more effective than using OpenAI's InstructGPT model alone.