Effort Engine
🌈 Abstract
The article discusses a new algorithm called "Effort" that can be used to adjust the number of calculations performed during the inference of large language models (LLMs). The algorithm allows for smooth and real-time adjustment of the calculation effort, enabling faster inference on Apple Silicon chips while retaining most of the model's quality. The article also mentions the ability to skip loading the least important weights, which can be seen as a form of ad-hoc distillation. The implementation is currently available for the Mistral model, and the author plans to extend it to other models as well.
🙋 Q&A
[01] Effort: A Possibly New Algorithm for LLM Inference
1. What is the main purpose of the "Effort" algorithm?
- The "Effort" algorithm allows users to smoothly and dynamically adjust the number of calculations performed during the inference of large language models (LLMs).
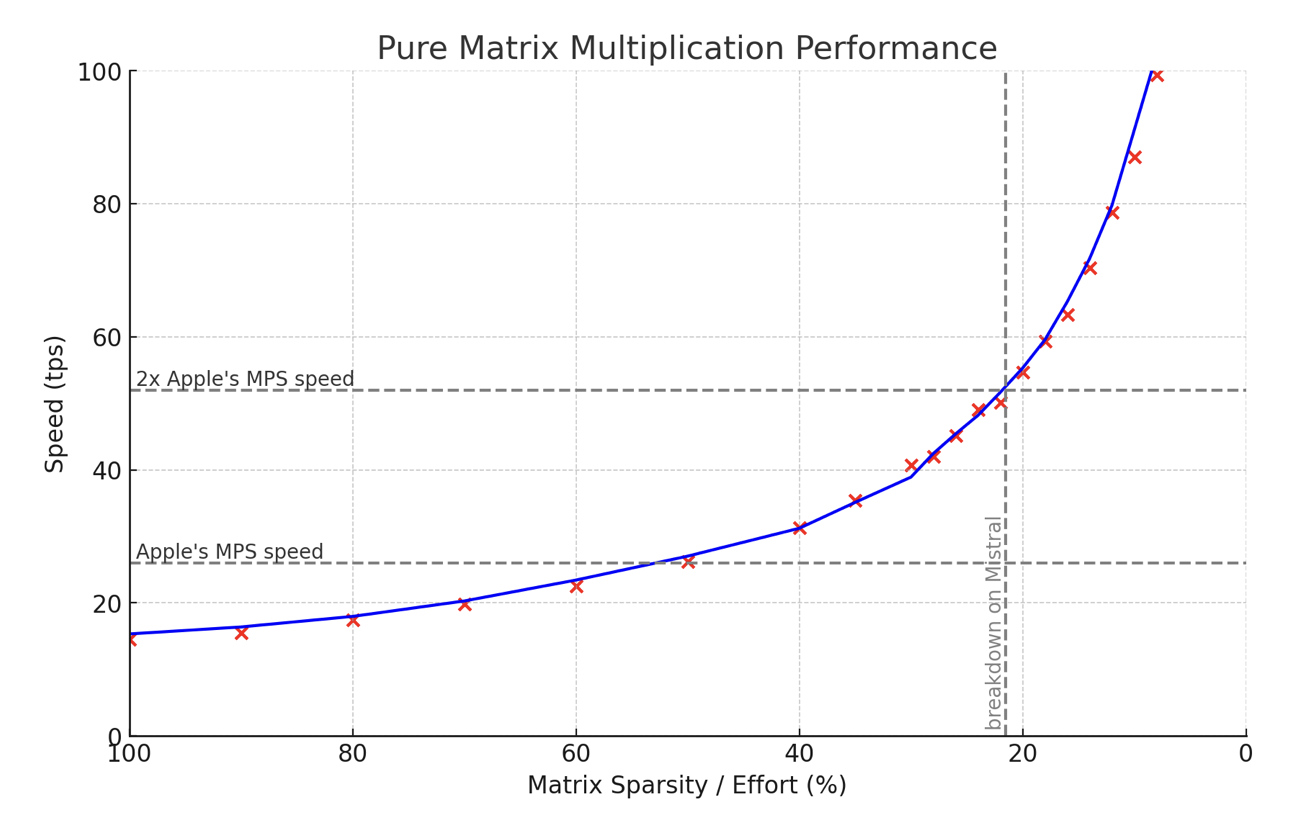
- This enables faster inference on Apple Silicon chips, with 50% calculations being as fast as regular matrix multiplications, and 25% effort being twice as fast while retaining most of the model's quality.
2. What are the key features of the "Effort" algorithm?
- It allows users to freely choose to skip loading the least important weights, which can be seen as a form of ad-hoc distillation.
- The implementation is currently available for the Mistral model, and the author plans to extend it to other models as well.
- No retraining is required, just conversion to a different format and some precomputation.
3. What are the current limitations of the "Effort" algorithm?
- The implementation is currently only available for FP16 (16-bit floating-point) operations.
- While the multiplications are fast, the overall inference is still slightly lacking because some non-essential parts, such as softmax, need improvement.
- The author is working on implementing Mixtral and Q8 (8-bit quantization) in the future.
[02] Benchmarks and Quality Assessments
1. How does the "Effort" algorithm perform in terms of speed and quality compared to regular inference?
- At 50% calculations, the "Effort" algorithm is as fast as regular matrix multiplications on Apple Silicon chips.
- At 25% effort, the algorithm is twice as fast while still retaining most of the model's quality.
2. What types of quality assessments have been performed on the "Effort" algorithm?
- The article mentions basic QA tests, but states that more thorough tests are needed, as outlined in the "Help Needed!" section.
- The initial results and undocumented experiments with Mixtral seem to be robust enough to warrant publication, but the author encourages readers to try the 0.0.1B version and provide feedback.
[03] Technical Details of the "Effort" Algorithm
1. What are the key components of the "Effort" algorithm?
- The article mentions the "bucketMul" component, the GPU implementation, and discussions around MoE (Mixture of Experts), quantization, and other technical details.
- The "Pesky details (or: Help Needed!)" section outlines areas where further work and testing are required.
2. What are the plans for future development and improvements of the "Effort" algorithm?
- The author plans to extend the implementation to other models beyond Mistral.
- The article mentions ongoing work on Mixtral and Q8 (8-bit quantization) implementations.
- The "Help Needed!" section indicates that the community's feedback and contributions are welcome to improve the algorithm further.