How To Solve LLM Hallucinations
🌈 Abstract
The article discusses the problem of hallucinations in large language models (LLMs) and a new approach called "Memory Tuning" developed by the startup Lamini to address this issue. It covers the following key points:
🙋 Q&A
[01] Large Language Models and Hallucinations
1. What is the problem of hallucinations in LLMs?
- LLMs can generate output that contains incorrect or fabricated information, known as "hallucinations".
- Hallucinations can occur due to:
- Lack of factual knowledge in the training data
- Models being designed to provide an answer, even if it is incorrect
- Embedding similar concepts together in the model's representation space
2. What are some existing approaches to address hallucinations?
- Domain-specific models: Trained only on data relevant to a specific domain, but can still have issues with contextual relationships.
- Co-prompting: Providing additional context data along with the user prompt, but computationally expensive.
- Fine-tuning: Starting with a general model and fine-tuning on curated data, but may not be accurate enough for some use cases.
- Retrieval Augmented Generation (RAG): Using a validated database to assist in generating output, but performance can vary.
- Mixture of Experts (MoE) models: Using multiple smaller, specialized models to route information to the most relevant expert.
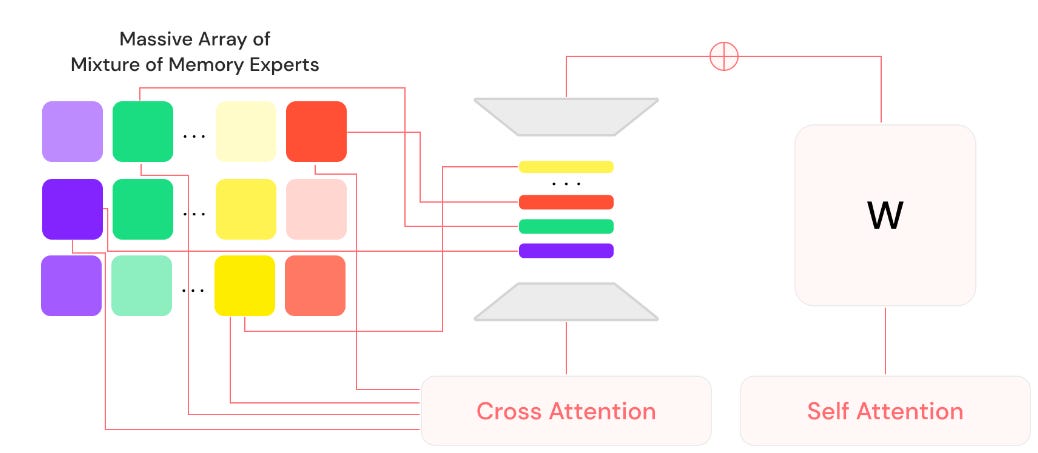
[02] Lamini's Memory Tuning Approach
1. What is Lamini's "Memory Tuning" approach?
- Lamini has developed a technique called "Memory Tuning" that can reduce hallucinations by up to 95%.
- It involves a "Mixture of Memory Experts" (MoME) approach, where each expert is tuned to a specific curated dataset at a very high rate (100x faster than regular fine-tuning).
- This allows the model to embed hard facts and specific domain knowledge while maintaining general reasoning capabilities.
2. How does Lamini's approach differ from conventional ML thinking?
- Conventional ML thinking is often hesitant to "overfit" data, as it was believed to degrade the model's general performance.
- However, Lamini's approach shows that the computational cost of this targeted tuning is much lower than regular fine-tuning, and has a negligible effect on the model's general reasoning.
3. What are the potential implications of Lamini's approach on computer architecture?
- The article suggests that Lamini's approach could lead to a shift in computer architecture, similar to the impact of transformers on computational requirements.
- The inference computational profile of a Lamini-tuned model may be substantially different from a standard model, potentially requiring changes in hardware design to optimize performance.
Shared by Daniel Chen ·
© 2024 NewMotor Inc.