Distance Metric Learning for Outlier Detection
🌈 Abstract
The article discusses the concept of outliers in data analysis and introduces a method called Distance Metric Learning (DML) for outlier detection. It covers the following key points:
🙋 Q&A
[01] Defining Outliers
1. How are outliers typically defined in a dataset?
- Outliers are records that are significantly different from the majority of other records in the dataset. They are more different from other records than is normal.
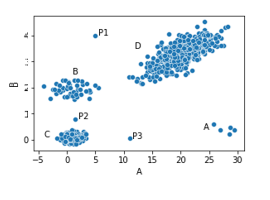
- Outliers can be identified as points that are far from the main clusters of data points.
- Inliers, on the other hand, are points that are very close to a significant number of other points.
2. What are some common approaches for outlier detection?
- Outlier detection methods based on Frequent Item Sets, Association Rules, compression, Markov Models, and algorithms like kNN, LOF (Local Outlier Factor), and Radius.
- These methods aim to identify records that are similar to few other records and relatively different from the records they are most similar to.
[02] Distance Metrics for Outlier Detection
1. What are some common distance metrics used for outlier detection?
- Euclidean distance, Manhattan distance, and Gower distance are commonly used distance metrics.
- Euclidean distance treats the data as points in high-dimensional space and calculates the physical distance between them.
- Manhattan and Gower distances are alternative metrics that can be more suitable for mixed data (numeric and categorical features).
2. What are the limitations of using generic distance metrics like Euclidean and Gower?
- They treat all features equally, whether or not that is the most appropriate approach.
- Some features may be more relevant than others, and there may be relationships between features that should be considered.
[03] Distance Metric Learning for Outlier Detection
1. How does Distance Metric Learning (DML) address the limitations of generic distance metrics?
- DML attempts to learn from the data itself how similar records are to each other, rather than just applying a predefined distance measure.
- It can identify which features are more relevant than others and account for relationships between features.
2. What is the key idea behind the DML-based outlier detection approach described in the article?
- The approach involves generating synthetic data that is similar but not identical to the real data, and then training a Random Forest classifier to distinguish the real from the synthetic data.
- The decision paths that records take through the Random Forest trees are then used to determine how similar the records are to each other, with records taking more unique paths being considered more anomalous.
3. How does the DML-based outlier detection method work in practice?
- The synthetic data is generated by sampling values for each feature independently, preserving the individual feature distributions but not the relationships between features.
- The trained Random Forest is then used to determine the leaf nodes that each record ends up in, with records ending in less common leaf nodes being considered more anomalous.
- The outlier scores are calculated based on the rarity of the leaf nodes that each record reaches in the Random Forest.
[04] Evaluation and Comparison
1. How does the DML-based outlier detection method perform compared to other approaches?
- The article demonstrates the DML-based method on two simple test datasets, showing that it can effectively identify outliers in both a single-cluster dataset and a multi-cluster dataset with outliers.
- Compared to Euclidean distance, the DML-based method can be more suitable for datasets with complex relationships between features.
2. What are the advantages and limitations of the DML-based outlier detection approach?
- Advantages:
- Can capture feature relevance and relationships in the data, which generic distance metrics may miss.
- Provides an intuitive way to quantify how anomalous each record is based on the decision paths in the Random Forest.
- Limitations:
- Requires tuning the synthetic data generation process and the Random Forest hyperparameters.
- May not be as effective as more sophisticated synthetic data generation techniques.
- Should be used in combination with other outlier detection methods for best results.