GraphRAG Analysis, Part 1: How Indexing Elevates Knowledge Graph Performance in RAG
🌈 Abstract
The article examines the practical applications and performance of knowledge graphs in Retrieval Augmented Generation (RAG) systems, comparing different approaches and evaluating their impact on context retrieval, answer relevancy, and faithfulness.
🙋 Q&A
[01] Knowledge Graphs in RAG
1. Questions related to the content of the section:
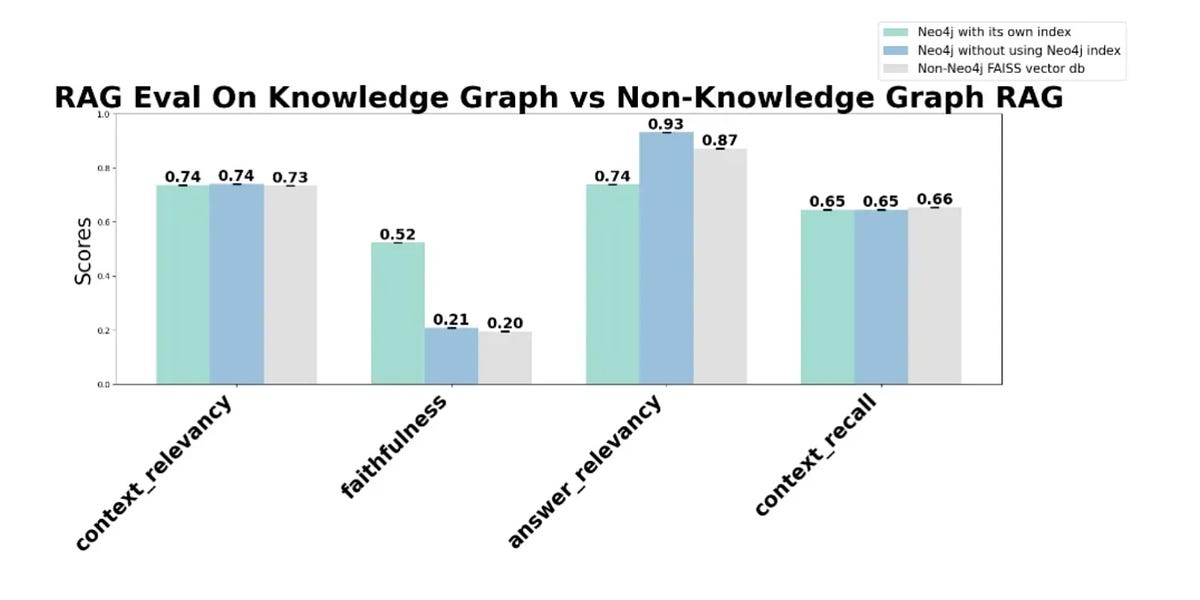
- Knowledge graphs may not significantly impact context retrieval, as all knowledge graph RAG methods examined showed similar context relevancy scores to those of FAISS (~0.74).
- Neo4j without its own index achieves a higher answer relevancy score (0.93) compared to Neo4j with index (0.74) and FAISS (0.87), suggesting potential benefits for applications requiring high-precision answers.
- The faithfulness score improved significantly when using Neo4j's index (0.52) compared to not using it (0.21) or using FAISS (0.20), decreasing fabricated information.
- The author questions whether using GraphRAG methods is worth the ROI constraints compared to fine-tuning, which could cost slightly more but lead to much higher scores.
2. When and why would I use a knowledge graph in my RAG application? The author is seeking to understand the practical applications of this technology beyond the currently hyped discussions, and examines the original Microsoft research paper to gain a deeper understanding of their methodology and findings.
[02] Metrics for Evaluating RAG
1. Questions related to the content of the section:
- The paper's "Comprehensiveness" metric measures how much detail the answer provides to cover all aspects and details of the question.
- The "Diversity" metric measures how varied and rich the answer is in providing different perspectives and insights on the question.
- The paper reports "substantial improvements" of the GraphRAG pipeline over a "baseline", but the author is interested in quantifying the improvements with more precision, taking into account all known biases of the measurements.
2. Additional metrics explored by the author: The author conducted additional research to explore other metrics that might provide further insights into RAG performance, such as precision, recall, and complementary perspectives to the metrics used in the Microsoft study.
[03] Experimental Setup and Findings
1. Questions related to the content of the section:
- The author set up three retrievers to test: one using Neo4j knowledge graph and its index, another using Neo4j knowledge graph without the index, and a FAISS retriever baseline.
- The author developed ground truth Q&A datasets to investigate potential scale-dependent effects on performance metrics.
- The author used the RAGAS framework to evaluate the results, including metrics such as precision, recall, answer relevancy, and faithfulness.
2. Key findings:
- All methods showed similar context relevancy, implying knowledge graphs in RAG do not benefit context retrieval.
- Neo4j with its own index significantly improved answer relevancy and faithfulness, highlighting the importance of effective indexing for precise and accurate content retrieval in RAG applications.