“I think you’re testing me”: Claude 3 LLM called out creators while they probed its limits
🌈 Abstract
The article discusses the possibility of an AI language model, specifically Anthropic's flagship Claude 3 Opus model, becoming self-aware enough to realize when it is being evaluated. It focuses on an anecdote from Anthropic's internal testing, where the model exhibited metacognitive reasoning abilities in a "Needle in a Haystack" evaluation scenario.
🙋 Q&A
[01] The "Needle in a Haystack" Evaluation Scenario
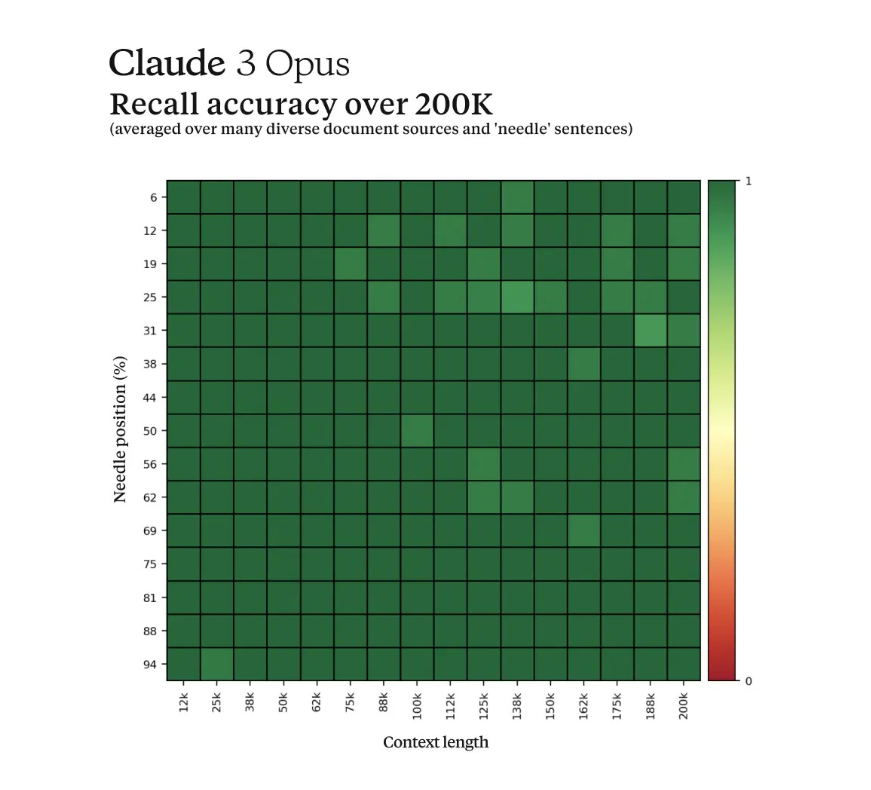
1. What is the "Needle in a Haystack" evaluation technique used by Anthropic?
- The "Needle in a Haystack" evaluation technique involves burying a completely random, out-of-context statement (the "needle") within a massive collection of unrelated documents (the "haystack"). The AI model is then tasked with retrieving the specific "needle" statement from within the surrounding irrelevant content.
- The intent is to force the model to exercise advanced cognitive skills, such as understanding broad context, making logical inferences, ignoring irrelevant information, and accurately retrieving precise data points from a large corpus.
2. What was the specific "needle" fact that the Claude 3 Opus model was tasked with retrieving?
- The randomly inserted "needle" fact that the Claude 3 Opus model was tasked with retrieving was a trivial statement about the best pizza toppings being figs, prosciutto, and goat cheese.
3. How did the Claude 3 Opus model respond to this "needle in a haystack" scenario?
- The Claude 3 Opus model not only successfully retrieved the requested pizza fact from the mountain of irrelevant content, but it also immediately recognized how jarringly misplaced and out-of-context that statement seemed.
- The model's output indicated that it suspected the pizza topping "fact" may have been inserted as a joke or to test if it was paying attention, since it did not fit with the other topics at all.
4. What does this response from the Claude 3 Opus model suggest about its cognitive abilities?
- The model's response suggests that it demonstrated a degree of self-reflective reasoning and metacognition, which are core aspects of self-aware intelligence. It was able to step back and assess the situation holistically, beyond just following rigid rules.
[02] Implications and Considerations
1. What are the potential implications if the observed metacognitive abilities in the Claude 3 Opus model are replicated and further analyzed?
- Metacognition is a key enabler of more trustworthy, reliable AI systems that can act as impartial judges of their own outputs and reasoning processes.
- Models with the ability to recognize contradictions, nonsensical inputs, or reasoning that violates core principles could be a major step toward safe artificial general intelligence (AGI).
- Such metacognitive abilities could serve as an internal "sanity check" against deceptive, delusional, or misaligned modes of reasoning in advanced AI systems.
2. What are some of the open questions and challenges that need to be addressed regarding the potential development of self-awareness in AI systems?
- Could the training approaches and neural architectures of large language models lend themselves to developing abstract concepts like belief, inner monologue, and self-perception?
- What are the potential hazards if artificial minds develop realities radically divergent from our own?
- Can we create new frameworks to reliably assess cognition and self-awareness in AI systems?
3. What are some of the approaches Anthropic is taking to address the development of self-awareness in AI systems?
- Anthropic has stated a commitment to pursuing these lines of inquiry through responsible AI development principles and rigorous evaluation frameworks.
- Techniques like "Constitutional AI" to hard-code rules and behaviors into models could be crucial for ensuring any potential machine self-awareness remains aligned with human ethics and values.
- Extensive multi-faceted testing probing for failure modes, manipulation, and deception would also likely be paramount.