Large Language Model Inference Acceleration Based on Hybrid Model Branch Prediction
🌈 Abstract
The paper proposes a hybrid model acceleration inference method based on branch prediction to reduce the validation time during hybrid model inference and accelerate the inference speed. The key points are:
- A branch-prediction function is constructed based on the binomial distribution assumption to fit the empirical distribution, further accelerating the inference speed.
- Experiments demonstrate that the proposed algorithm achieves better acceleration effects in tasks of generating combinations of models of different scales.
🙋 Q&A
[01] Introduction
1. Questions related to the content of the section?
- The paper proposes a hybrid model acceleration inference method based on branch prediction to reduce the validation time and accelerate the inference speed.
- It constructs a branch-prediction function based on the binomial distribution assumption to further accelerate the inference speed.
- Experiments show the proposed algorithm achieves better acceleration effects when generating combinations of models of different scales.
[02] Related Work
No specific questions or answers provided, as the section title "Related Work" was not included in the document.
[03] Prior Knowledge
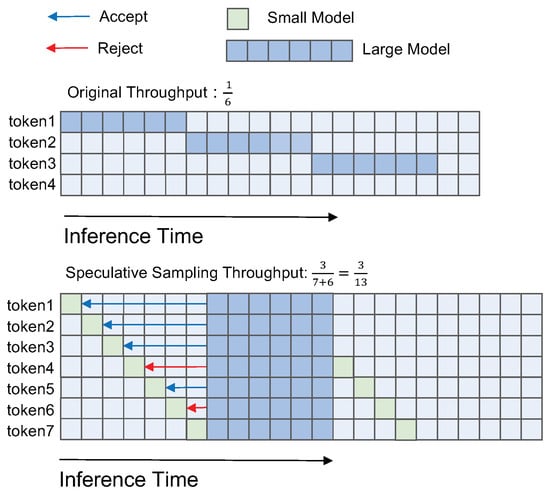
1. What is speculative sampling?
- The smaller model is used to quickly generate a series of inference output draft characters (tokens).
- These drafts are then verified and, if necessary, corrected by the original large model.
- The number of accepted drafts is defined as the starting point for the next round of small model inference.
2. What is branch prediction?
- Static prediction relies on simple rules, such as always predicting a branch will go in a specific direction.
- Dynamic prediction depends on information collected at runtime, predicting future branch decisions based on historical branch behavior.
[04] Methods
1. What are the key steps of the hybrid model inference acceleration algorithm based on branch prediction?
- Small Model Draft Generation: The small model generates draft tokens as potential generation output.
- Branch Prediction: A prediction function is used to predict the number of acceptable drafts.
- Large Model Validation: The large model evaluates the draft tokens and determines the actual number of accepted drafts.
- Branch-Prediction Result Check: The prediction for the current round is checked after large model validation.
2. How is the prediction function designed for acceleration?
- The prediction function is based on the binomial distribution assumption and the empirical distribution analysis.
- It aims to fit the observed frequency distribution and accurately predict the number of accepted drafts.
[05] Analysis
No specific questions or answers provided, as the section title "Analysis" was not included in the document.
[06] Experiments
1. What are the key findings from the experiments?
- The branch-prediction algorithm achieves better acceleration effects compared to speculative sampling, especially when combining models of different scales.
- The single-round token generation quantity has an impact on the acceleration effect.
- An extreme trade-off strategy exploring exhaustive methods is also explored.
[07] Conclusions
No specific questions or answers provided, as the section title "Conclusions" was not included in the document.