Teaching chat models to solve chess puzzles
🌈 Abstract
The article discusses experiments conducted to improve the chess puzzle solving performance of chat models, such as GPT-4o-mini, by combining fine-tuning and prompt optimization techniques. It compares the performance of completion models (e.g., babbage-002, davinci-002) and chat models, and presents the results of various approaches to boost the accuracy of the chat models.
🙋 Q&A
[01] Improving Chat Model Performance
1. What techniques were used to improve the chess puzzle solving performance of chat models?
- The article discusses using automatic prompt optimization with tuned few-shot examples using the DSPy framework, as well as fine-tuning the GPT-4o-mini model on the optimized chain-of-thought outputs from GPT-4o.
2. How did the performance of the chat models compare to the completion models?
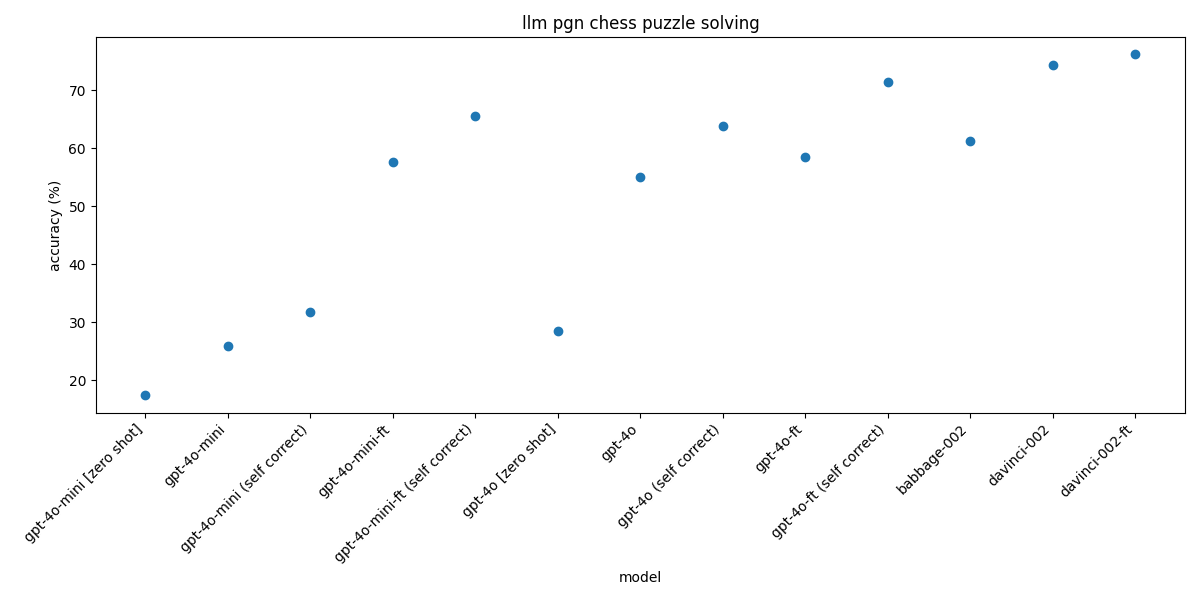
- Without any examples, the chat model performance was poor, with GPT-4o-mini solving only 17.4% of the puzzles and GPT-4o solving 28.44%.
- The completion models, babbage-002 and davinci-002, performed much better, with 61.23% and 74.45% accuracy, respectively.
3. How did the performance of the chat models improve after applying the optimization techniques?
- By optimizing the prompt with DSPy and using few-shot examples, the accuracy of GPT-4o-mini improved to 25.99%, a 50% increase over the zero-shot baseline.
- Combining this with a self-correction step for illegal moves and 2 retries, the accuracy further improved to 31.72%.
- When the optimized prompt was used with the stronger GPT-4o model, the accuracy increased to 63.88%.
4. How did fine-tuning the chat models impact their performance?
- By fine-tuning the GPT-4o-mini model on the optimized chain-of-thought outputs from GPT-4o, the accuracy improved to 65.64%, a 280% improvement over the zero-shot baseline.
- Fine-tuning the stronger GPT-4o model on the same data resulted in an accuracy of 71.37%, nearly matching the performance of the davinci-002 completion model.
[02] Comparison of Completion and Chat Models
1. How did the performance of the completion models compare to the fine-tuned chat models?
- The fine-tuned GPT-4o-mini model achieved 65.64% accuracy, beating the babbage-002 completion model (61.23%) but losing to the davinci-002 completion model (74.45%).
- The fine-tuned GPT-4o model achieved 71.37% accuracy, nearly matching the performance of the davinci-002 completion model.
2. What was the impact of fine-tuning the davinci-002 completion model?
- Fine-tuning the davinci-002 completion model with just the PGN-move pairs resulted in a modest improvement, increasing the accuracy from 74.45% to 76.21%.
3. What were the key takeaways from the experiments?
- The article suggests that the best approach is to first use DSPy with a cheap model to get a good prompt, then use the optimized prompt with a stronger model to create a fine-tuning dataset. Fine-tuning the cheap model on this dataset can make its performance competitive with the expensive teacher model.