What is Learned in Knowledge Graph Embeddings?
🌈 Abstract
The article investigates what knowledge graph (KG) embedding models actually learn by proposing three distinct learning mechanisms: unstructured statistical learning, network learning, and motif learning. The authors conduct experiments on both synthetic and real-world KGs to understand the contributions of these mechanisms and provide insights into the strengths and limitations of various embedding models.
🙋 Q&A
[01] Knowledge Graphs and Embedding Models
1. What are the key characteristics of knowledge graphs (KGs)?
- KGs represent entities as vertices and their relationships as typed, directed edges, enabling flexible information organization and automated reasoning.
- KGs have proven valuable in diverse applications like natural language processing, recommendation systems, and drug discovery due to their ability to capture complex relationships in a machine-readable format.
2. What are the goals of KG embedding models?
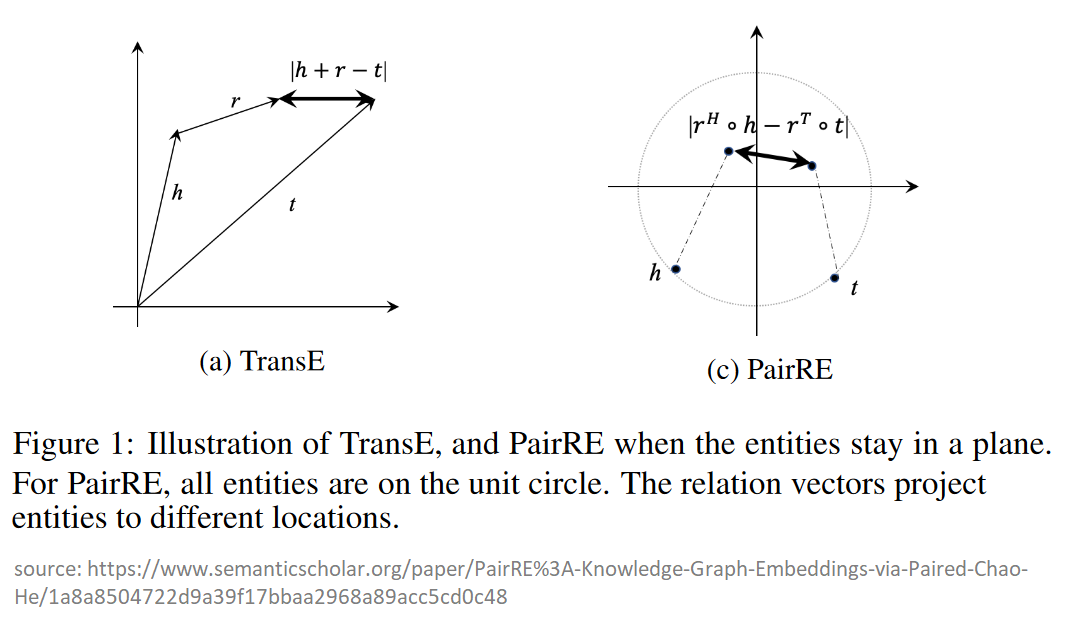
- KG embedding models aim to map entities and relations to low-dimensional vector representations (embeddings) in a metric space, where the proximity between entities under a relation-type-dependent transformation reflects the likelihood of the corresponding edge existing in the KG.
- Two popular embedding models are TransE and PairRE, which use different approaches to learn the embeddings.
3. How do KG embedding models address the computational challenges of training on large-scale KGs?
- To address the computational challenges of training on large-scale KGs, negative sampling is used to estimate the error for triples not present in the KG. This involves generating negative triples by corrupting positive triples and training the model to score positive triples higher than negative triples.
[02] Link Prediction and Evaluation Metrics
1. What are the two common applications of link prediction for KG embedding models?
- Binary link classification: Predicting whether a given triple (head, relation, tail) is likely to be true or false.
- Ranking of potential link completions: Ranking the potential candidates for the missing entity in a partial triple (e.g., (head, relation, ?)).
2. What are the two common metrics used to evaluate the performance of KG embedding models on link prediction tasks?
- Hits@N: Measures the proportion of correct entities ranked in the top N predictions.
- Mean Reciprocal Rank (MRR): Computes the average of the reciprocal ranks of the correct entities.
[03] Three Learning Mechanisms in KG Embeddings
1. What is unstructured statistical learning, and how does it differ from other learning mechanisms?
- Unstructured statistical learning focuses on modeling the probability distribution of triples (h, r, t) using latent variables, without explicitly considering the graph structure or logical rules between relations.
- It relies on the statistical co-occurrence of entities and relations within the KG to make predictions, learning embeddings that capture these statistical patterns.
2. How does network learning capture the structural properties of the knowledge graph?
- Network learning leverages the connectivity patterns and topology of the graph to learn embeddings that reflect the proximity and relatedness of entities, without explicitly considering the semantic meaning of the relations.
- It aims to learn embeddings where entities that are closer in the graph have more similar embeddings.
3. What is motif learning, and how does it help capture rules between relations in KG embeddings?
- Motif learning is a mechanism for discovering rules between relations in knowledge graph embeddings by optimizing the relation embeddings to satisfy the constraints implied by recurring subgraphs (motifs) within the knowledge graph.
- This allows the model to capture logical rules or constraints between relations, such as compositional patterns.
[04] Experiments on Synthetic Knowledge Graphs and Real-World Datasets
1. How did the authors use synthetic knowledge graphs to isolate and test the different learning mechanisms?
- The authors constructed synthetic KGs with a highly structured deterministic graph (G) and a random graph representing noise (R). This setup allowed them to control the noise levels and test specific structural patterns.
- They used variants of TransE, such as TransE*, to isolate the contribution of network learning by freezing the relation embeddings during training.
2. How did the authors distinguish the learning mechanisms in real-world knowledge graphs?
- For real-world KGs, the authors used simple models like RE (Relation-Entity) as baselines to measure the contribution of unstructured statistical learning.
- They also created versions of the KGs with all relation types removed to isolate the impact of graph structure on model performance (network learning).
- To test pattern learning, the authors analyzed the learned embeddings to check if they satisfy expected motif patterns and evaluated models on tasks requiring understanding of specific logical rules or patterns.
3. What methodological insights did the authors provide for evaluating knowledge graph embeddings?
- The authors suggested increasing the number and diversity of negative examples in link prediction tasks to provide a more challenging and representative test.
- They introduced the use of resampled metrics (R-MRR) alongside standard metrics to get a more accurate assessment of model performance, especially for large KGs where uniform sampling of negatives can be misleading.