Consistency Large Language Models: A Family of Efficient Parallel Decoders
🌈 Abstract
The article introduces Consistency Large Language Models (CLLMs), a new family of parallel decoders that can efficiently decode an n-token sequence per inference step, reducing the inference latency of traditional sequential decoders in large language models (LLMs).
🙋 Q&A
[01] Consistency Large Language Models (CLLMs)
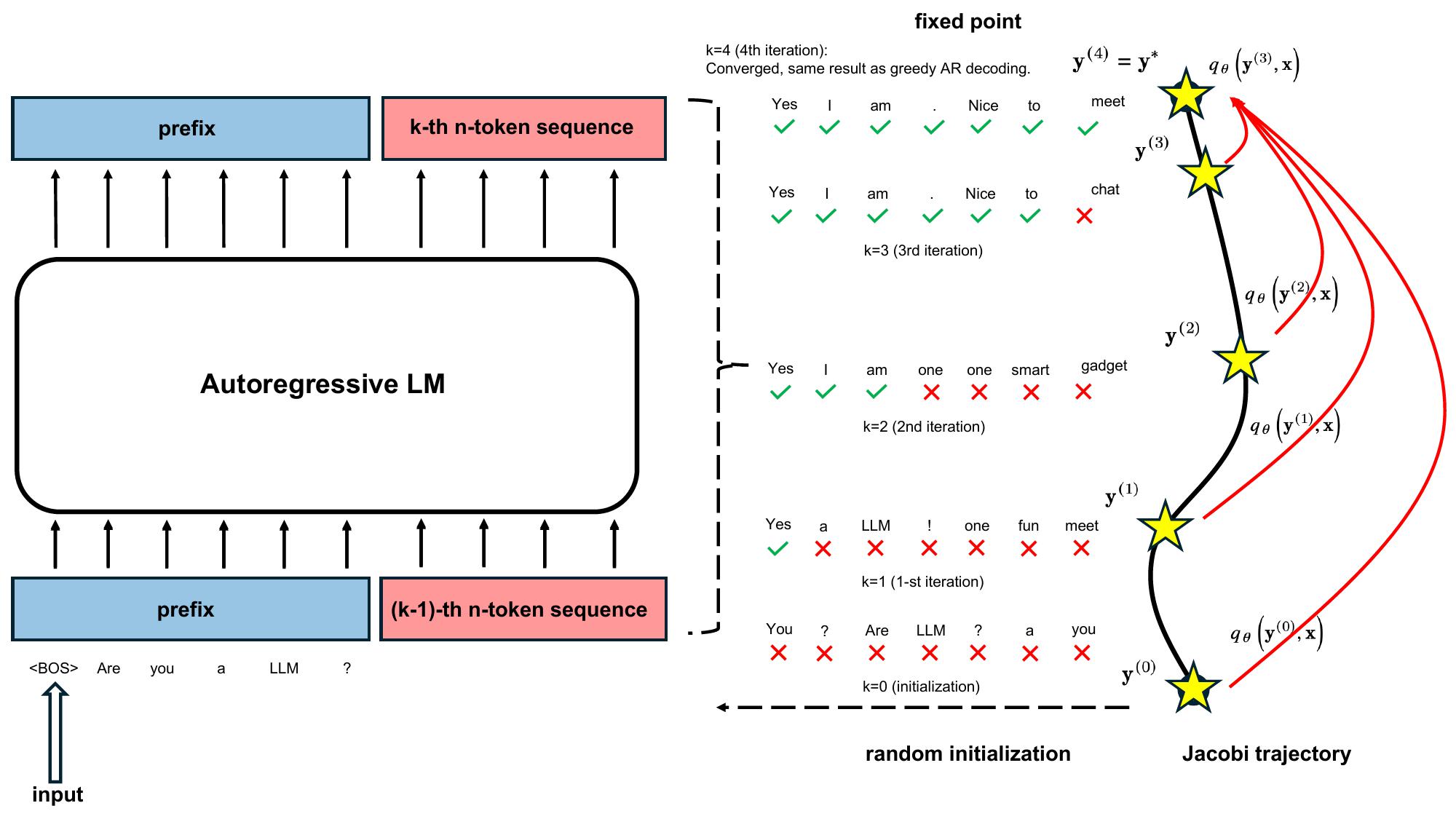
1. What are CLLMs and how do they differ from traditional LLMs?
- CLLMs are a new family of parallel decoders that can decode an n-token sequence per inference step, in contrast to traditional LLMs that generate responses token-by-token using autoregressive (AR) decoding.
- CLLMs are trained to perform parallel decoding by mapping any randomly initialized n-token sequence to the same result yielded by AR decoding in as few steps as possible.
2. How do CLLMs achieve faster generation compared to other techniques?
- CLLMs exhibit two key phenomena that contribute to faster convergence in Jacobi decoding:
- Fast forwarding: CLLMs can correctly predict multiple consecutive tokens in a single Jacobi iteration.
- Stationary tokens: CLLMs can preemptively predict correct tokens and ensure they remain unchanged, even with preceding incorrect tokens.
- These capabilities allow CLLMs to acquire proficiency in linguistic collocations and predict multiple words simultaneously, minimizing the number of iteration steps required.
3. What are the advantages of CLLMs compared to other fast inference techniques?
- CLLMs achieve improvements in generation speed that are on par with or better than other techniques like Medusa2 and Eagle, yet require no additional memory cost for auxiliary model components at inference time.
- CLLMs also exhibit higher adaptability as they can be obtained by simply fine-tuning pre-trained LLMs, without requiring modifications to the target model's original architecture.
[02] Evaluation and Experiments
1. How were the CLLMs evaluated and what were the key findings?
- The experiments were conducted on three domain-specific tasks (Spider, Human-Eval, GSM8k) and the open-domain conversational challenge MT-bench.
- Compared to other baselines, including the original target model, Medusa2, and speculative decoding, CLLMs achieved the most significant speedup on the specialized domain tasks.
- On the MT-bench open-domain challenge, CLLMs trained from LLaMA2-7B achieved roughly the same speedup as Medusa2 when combined with lookahead decoding, while offering higher adaptability and memory efficiency.
2. What was the cost of fine-tuning CLLMs?
- The fine-tuning cost of CLLMs was moderate, requiring only around 1 million tokens for LLaMA-7B to achieve a speedup on the Spider dataset.
- For larger datasets, such as CodeSearchNet-Python, only 10% of the dataset was required to generate Jacobi trajectories and train CLLMs to obtain around 2x speedup.
Shared by Daniel Chen ·
© 2024 NewMotor Inc.