How to Use Hybrid Search for Better LLM RAG Retrieval
🌈 Abstract
The article discusses the Retrieval-Augmented Generation (RAG) pipeline, which uses an encoder model to search for similar documents when given a query. It covers three main search approaches:
- Keyword Search with BM25
- Semantic Search with Dense Embeddings
- Hybrid Search, which combines the benefits of keyword and semantic search
🙋 Q&A
[01] RAG Retrieval
1. What is the purpose of the RAG pipeline? The RAG pipeline uses an encoder model to search for similar documents when given a query. This is also called semantic search, as the encoder transforms text into high-dimensional vector representations (embeddings) where semantically similar texts are close together.
2. What was the BM25 algorithm used for before the advent of Large Language Models (LLMs)? Before LLMs, the BM25 algorithm was a very popular search algorithm. BM25 focuses on important keywords and looks for exact matches in the available documents, which is called keyword search.
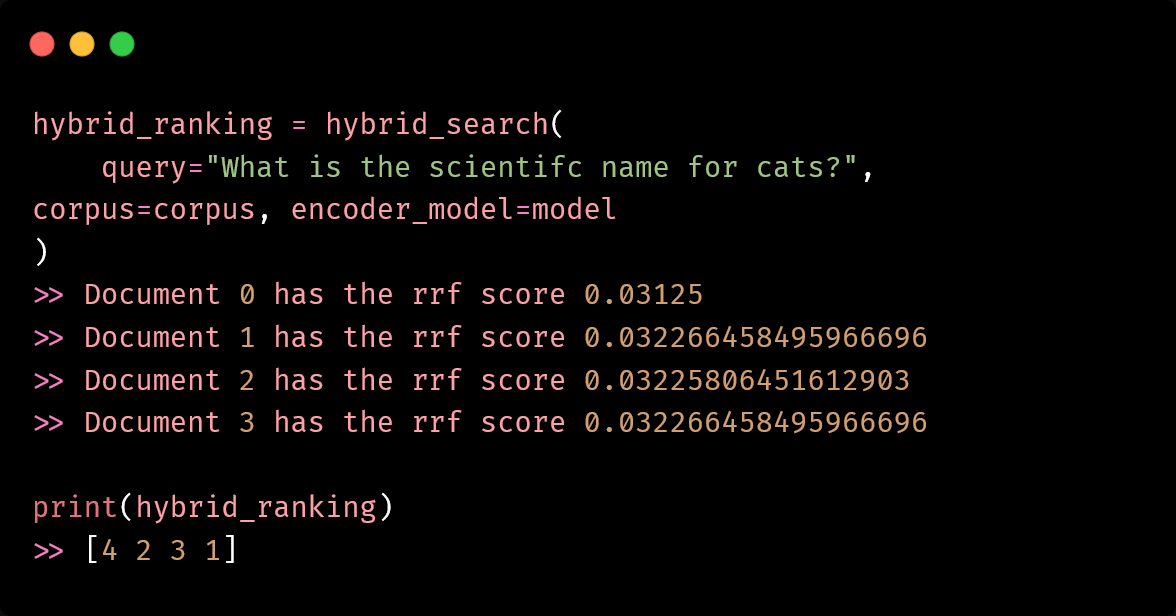
3. How does hybrid search combine keyword and semantic search? Hybrid search combines the benefits of keyword search and semantic search to improve search quality. It uses both BM25 and cosine similarity with dense embeddings, and then combines the results using Reciprocal Rank Fusion (RRF).
[02] Keyword Search With BM25
1. What is the core idea behind the TF-IDF algorithm that BM25 is based on? The TF-IDF algorithm is based on the idea that "matches on less frequent, more specific, terms are of greater value than matches on frequent terms". In other words, it looks for documents that contain rare keywords from the query.
2. How does the ATIRE BM25 formula work? The ATIRE BM25 formula sums over all terms in the query, taking into account the number of documents containing the term (inverse document frequency) and the number of occurrences of the term in the document (term frequency). It also considers the length of the document and the average document length.
3. How does BM25 perform on queries with exact phrase matches vs. queries with synonyms or different spellings? BM25 performs well on queries looking for exact phrase matches, as it focuses on finding documents with the exact query terms. However, it struggles with queries that use synonyms or different spellings, as it relies on exact term matches.
[03] Semantic Search With Dense Embeddings
1. How do text embeddings work? Text embeddings are high-dimensional vector representations of words or sentences, where similar words/texts are close together in the vector space. They are created by first converting words to tokens, and then using a neural network encoder model to transform the tokens into the embeddings.
2. How is cosine similarity used to measure the similarity between embeddings? Cosine similarity measures the angle between two embedding vectors. A cosine similarity score of 1 means the vectors are identical, 0 means they are orthogonal (unrelated), and -1 means they are opposite. Cosine similarity is equivalent to dot product similarity if the embeddings are normalized.
3. How does semantic search perform compared to keyword search? Semantic search performs better than keyword search when the query uses synonyms or different spellings, as it can find semantically similar documents even if the exact query terms are not present. However, it may not perform as well as keyword search for queries looking for exact phrase matches.
[04] Semantic Search or Hybrid Search?
1. What are the main advantages and disadvantages of keyword search and semantic search? Keyword search with BM25 is good for finding exact matches of phrases, such as for specific functions or code. Semantic search is better at finding semantically similar content, even if the exact query terms are not present.
2. How does hybrid search combine the strengths of keyword and semantic search? Hybrid search uses both BM25 keyword search and cosine similarity with dense embeddings, and then combines the results using Reciprocal Rank Fusion (RRF). This allows it to benefit from the strengths of both approaches.
3. What are the tradeoffs of using hybrid search compared to a single search approach? The main tradeoff of hybrid search is that it requires more computational resources, as it runs both keyword and semantic search. However, the improved search quality may be worth the additional cost in many applications.
[05] Putting It All Together
1. How does the author's implementation of hybrid search work? The author implements hybrid search by first running BM25 keyword search and cosine similarity semantic search separately, then combining the results using the Reciprocal Rank Fusion (RRF) algorithm.
2. What are some next steps the author suggests for improving the RAG pipeline? The author suggests adding more knowledge to the corpus of documents, such as by integrating Wikipedia. They also mention adding a re-ranker on top of the hybrid search to further improve the overall RAG pipeline.
3. What are the key takeaways from the article? The key takeaways are:
- Hybrid search combines the strengths of keyword search and semantic search
- Hybrid search requires more computational resources but can improve overall search quality
- Hybrid search is a useful building block for improving RAG pipelines, but can be further enhanced with additional techniques