Prompt Engineering: Classification of Techniques and Prompt Tuning
🌈 Abstract
The article discusses the emerging field of prompt engineering, including a classification of prompt engineering techniques and the process of prompt tuning and evaluation. It covers common rules for writing effective prompts, different categories of prompt engineering techniques (single prompt, multiple prompt, and LLM frameworks with external tools), and the importance of treating prompt engineering as a data science process.
🙋 Q&A
[01] Prompt Engineering: Classification of Techniques and Prompt Tuning
1. What are the major pitfalls of large language models (LLMs) discussed in the article?
- Citing resources: LLMs cannot cite external resources as they do not have access to the internet.
- Bias: LLMs can exhibit bias and generate stereotypical or prejudiced content.
- Hallucinations: LLMs can generate false information when asked a question they do not know the answer to.
- Math and commonsense problems: LLMs often struggle with solving even simple mathematical or commonsense problems.
- Prompt hacking: LLMs can be manipulated by users to ignore developers' instructions and generate specific content.
2. What are the common rules for writing effective prompts discussed in the article?
- Be precise in stating what the model should do (write, summarize, extract information).
- Avoid saying what not to do and instead state what to do.
- Be specific, e.g., "in 2-3 sentences" instead of "in a few sentences".
- Add tags or delimiters to structure the prompt.
- Ask for a structured output (JSON, HTML) if needed.
- Ask the model to verify if it does not know the answer.
- Ask the model to first explain and then provide the answer.
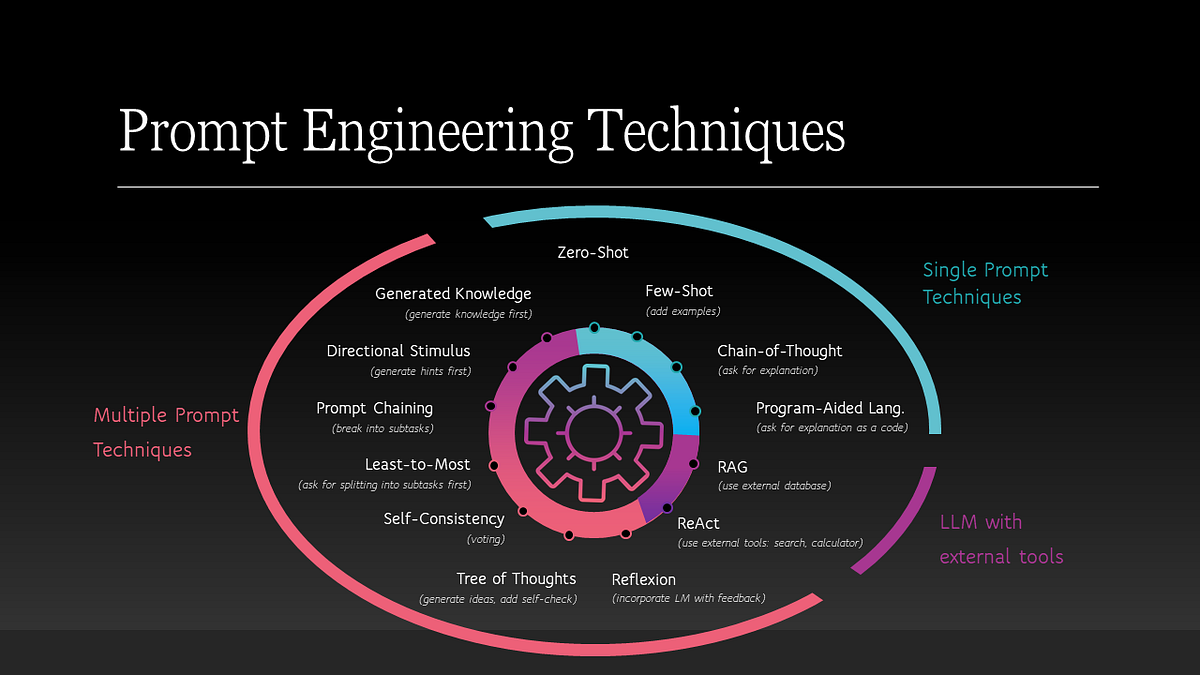
3. What are the three main groups of prompt engineering techniques discussed in the article?
- Single prompt techniques: Zero-Shot, Few-Shot, Chain of Thought, Program Aided Language.
- Techniques that combine multiple prompts: Voting (Self-Consistency), Divide and conquer (Directional Stimulus, Generated Knowledge, Prompt Chaining, Least-to-Most, Chain-of-Table), Self-evaluation (Reflexion, Tree-of-Thoughts).
- Techniques that combine LLMs with external tools: Retrieval Augmented Generation (RAG), ReAct.
[02] Prompt Tuning and Evaluation
1. Why is it important to treat prompt engineering as a data science process? Prompt engineering is sensitive to small changes in human-generated prompts, which are often suboptimal and subjective. Treating it as a data science process involves creating a test set, choosing metrics, tuning the prompts, and evaluating their influence on the test set.
2. What are some of the metrics suggested for testing and evaluating prompts?
- Faithfulness and relevancy: how factually accurate and relevant the generated answer is.
- Retrieval (for RAG and ReAct pipelines): precision and recall of the retrieved documents.
- Internal thinking: accuracy of agent and tool selection, tool argument extraction, remembering facts in long-term conversation, and correct logical steps.
- Non-functional: style and tone, absence of bias, compliance and safety checks, and prompt injection testing.
3. What are the key rules for writing effective prompts summarized in the article?
- Be clear and precise so that the model doesn't have to guess your intentions.
- Use delimiters or tags to add structure.
- Help the model by showing examples and adding explanations.
- Ask the model to think iteratively, explaining its solution.
- Consider splitting a complicated prompt into subtasks.
- Try asking the same prompt a few times.
- Consider adding a step of model self-check.
- Combine the LLM with external tools if needed.
- Treat prompt tuning as a data science process that is iterative and requires evaluation.