Evidence that LLMs are reaching a point of diminishing returns - and what that might mean
🌈 Abstract
The article discusses the possibility that large language models (LLMs) are reaching a point of diminishing returns, where the rate of improvement in their capabilities is slowing down. It challenges the conventional wisdom that LLMs are advancing exponentially, and presents evidence that suggests a plateau in their progress.
🙋 Q&A
[01] Evidence of Diminishing Returns
1. What are the key points made about the evidence of diminishing returns in LLM progress?
- The article argues that the study cited by Ethan Mollick, which claims LLM capabilities are doubling every 5-14 months, does not actually show that. The study only shows that the computational resources required to achieve a given level of performance have been halving every 8 months, not that capabilities are doubling.
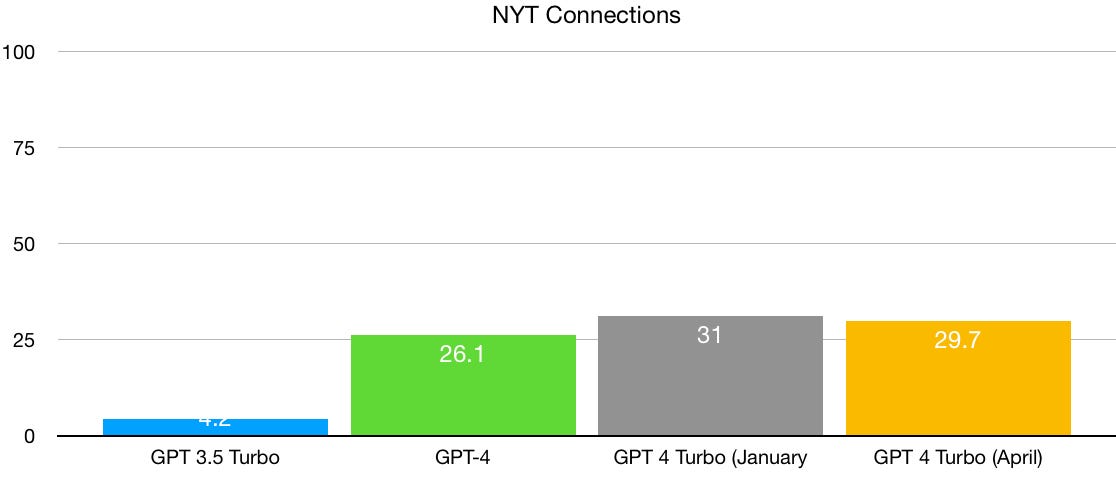
- The author presents several graphs showing the performance of different LLM versions (GPT-2, GPT-3, GPT-4, GPT-4 Turbo) on benchmarks like MMLU and the New York Times Connections game. These graphs suggest that the rate of improvement has slowed down, with only modest gains between the latest versions.
- The author also notes that as models approach the top of performance metrics, the "restriction of range" problem can make it harder to see continued exponential progress.
- Qualitative evidence is also discussed, with the author arguing that issues like hallucinations and errors in LLMs have not been solved, despite the release of newer models.
2. What are the implications of diminishing returns in LLM progress?
- If LLMs are indeed reaching a plateau in their progress, it may mean that they will never live up to the "wild expectations" of last year. The author suggests that a "correction" could be coming, with market valuations of LLM-focused companies potentially plummeting.
- The author argues that reliable, trustworthy AI may require going "back to the drawing board" rather than relying solely on the continued advancement of LLMs.
[02] Comparison to Previous Warnings
1. What previous warnings did the author make about the limitations of LLMs? The author mentions that in 2022, they had warned about issues like hallucinations and "stupid errors" in LLMs, which the author argues have not been solved despite the release of newer models.
2. How does the current evidence of diminishing returns relate to the author's previous warnings? The author suggests that the current evidence of diminishing returns in LLM progress aligns with the warnings they had made in 2022 about the limitations of LLMs. The author sees the current situation as a potential "wall" that they had previously warned about.