OLMo 1.7–7B: A 24 point improvement on MMLU
🌈 Abstract
The article discusses the release of an updated version of the Open Language Model (OLMo 1.7-7B), a 7 billion parameter language model. Key points include:
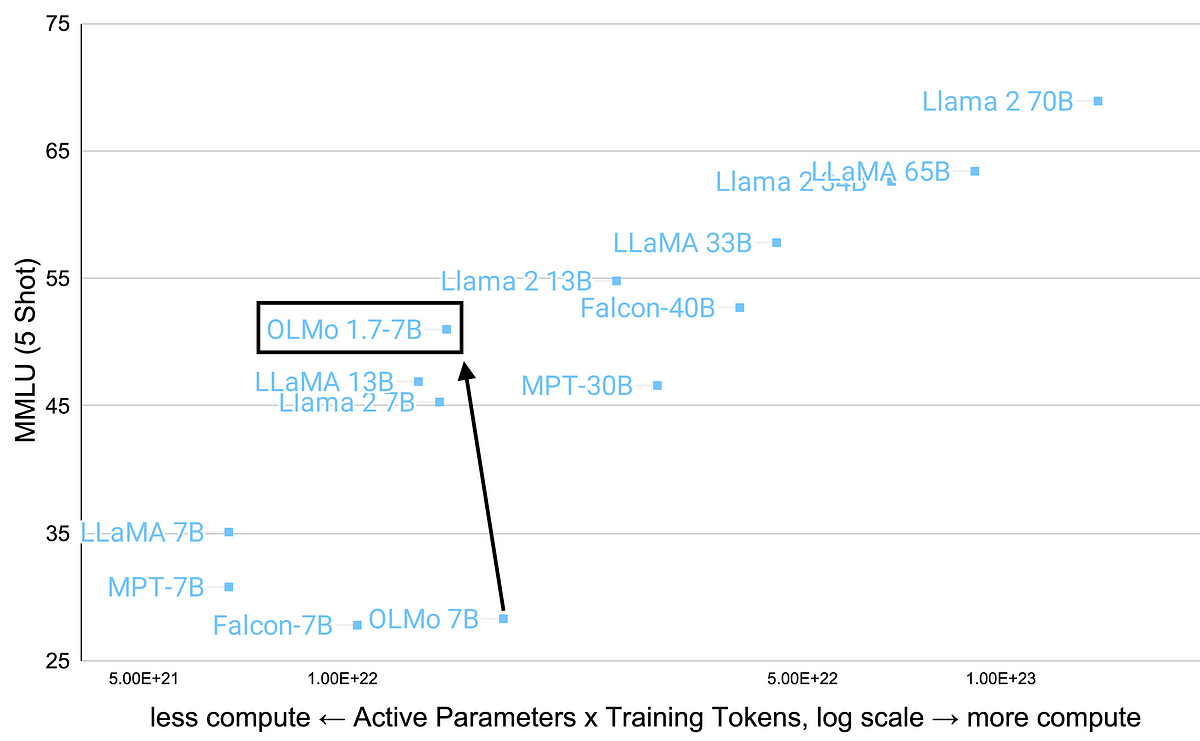
- OLMo 1.7-7B outperforms Llama 2-13B on the GSM8K benchmark and scores 52 on MMLU, approaching the performance of Llama 2-13B.
- The model has a longer context length of 4096 tokens, up from 2048 in the previous version.
- Improvements come from better data quality, a new two-stage training procedure, and architectural changes.
- The training dataset, Dolma 1.7, has been expanded to include more diverse sources and improved deduplication and quality filtering.
- OLMo 1.7-7B was trained on Databricks with support from partners like AMD, CSC LUMI supercomputer, and the University of Washington.
🙋 Q&A
[01] Model Performance and Training
1. What are the key improvements in OLMo 1.7-7B compared to the previous version?
- Longer context length, up from 2048 to 4096 tokens
- Higher benchmark performance on MMLU and GSM8K
- Combination of improved data quality, new two-stage training procedure, and architectural improvements
2. How does the compute efficiency of OLMo 1.7-7B compare to other language models? OLMo 1.7-7B shows substantially higher compute efficiency per performance relative to models like the Llama suite and Mosaic Pretrained Transformer (MPT).
3. What are the key differences between the Dolma 1.5 and Dolma 1.7 datasets used to train OLMo?
- More diverse sources in Dolma 1.7, including content from arXiv, Stack Exchange, OpenWebMath, and Flan to improve performance on specialized knowledge and complex reasoning tasks
- Better deduplication in Dolma 1.7, including fuzzy deduplication at the document level
- Quality filtering using a FastText classifier to distinguish high-quality and low-quality text
[02] Training Procedure
1. What are the two stages of the training procedure for OLMo 1.7-7B?
- Initial training from scratch on the full Dolma 1.7 dataset with a cosine learning rate schedule.
- Further training on a curated high-quality subset of Dolma 1.7, with linear decay of the learning rate to 0.
2. What are the key differences in the data used in the two training stages?
- Stage 1: Full Dolma 1.7 dataset
- Stage 2: Curated subset, including all available Wikipedia, OpenWebMath and Flan data, and rebalanced remaining sources
3. What is the motivation behind the two-stage training procedure? The two-stage approach allows the model to first learn from the full Dolma 1.7 dataset, and then further fine-tune on a high-quality curated subset to improve performance.