Is “Embeddings” killing Embeddings?
🌈 Abstract
The article discusses the pushback against the use of embeddings in AI and the challenges in explaining this concept to non-technical or non-mathematical people.
🙋 Q&A
[01] Explaining Embeddings
1. What are embeddings according to OpenAI and McKinsey?
- According to OpenAI, embeddings are vectors (lists) of floating-point numbers where the distance between two vectors measures their relatedness. Small distances suggest high relatedness and large distances suggest low relatedness.
- According to McKinsey, embeddings are created by assigning each item from incoming data to a dense vector in a high-dimensional space. Since close vectors are similar by construction, embeddings can be used to find similar items or to understand the context or intent of the data.
2. Why do people have a pushback against using the term "embeddings"?
- The term "embeddings" makes it sound like something is being put "inside" the prompt or input, which is not intuitive for people. The mathematical meaning of embeddings as a structure contained within another structure does not align with how people understand the term "embed" in everyday language.
- People understand concepts like "Prompt Engineering" and "Fine-Tuning" better because the terms are more intuitive and describe the actual actions being performed. "Embeddings" sounds more abstract and complex.
3. How does the author suggest explaining embeddings instead?
- The author suggests describing embeddings as a "source translation" process, where the input is translated into a format that the model can better understand, and then comparisons can be made between these translated representations.
- This framing focuses on the practical purpose of embeddings (translating input to a format the model can use) rather than the technical details of the mathematical structure.
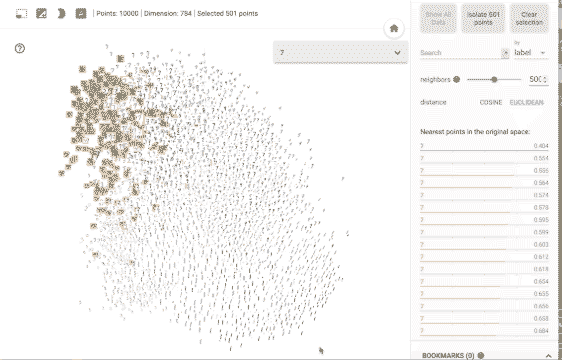
- The author also suggests using visual aids like the TensorFlow Embeddings Projector to help concretize the concept of embeddings for non-technical audiences.
[02] Simplifying Explanations
1. What is the author's key point about simplifying explanations?
- The author emphasizes the importance of explaining complex technical concepts in a way that makes sense to the listener's perspective, rather than using jargon or assuming the listener has the same level of expertise.
- The author uses the example of a surgeon explaining a procedure to a patient - the surgeon simplifies the explanation to the patient's level of understanding, rather than using highly technical medical terminology.
- Similarly, the author suggests that when explaining AI concepts like embeddings, data scientists should translate the technical details into more intuitive, relatable terms that the audience can understand.
2. What is the author's advice for avoiding "sounding clever" when explaining technical concepts?
- The author advises against assuming the listener has the same level of context and expertise as the speaker.
- Instead, the author recommends thinking about the listener's perspective and translating the concepts into language and examples that make sense in the listener's world.
- The goal should be to build trust and understanding, rather than impressing the listener with technical jargon.
3. What is the author's final recommendation for explaining embeddings?
- The author suggests using a term like "source translation" to describe the process of converting the input data into a format the model can better understand.
- This framing focuses on the practical purpose of embeddings, rather than the technical mathematical details.
- The author also encourages the use of visual aids, like the TensorFlow Embeddings Projector, to help concretize the concept of embeddings for non-technical audiences.
Shared by Daniel Chen ·
© 2024 NewMotor Inc.