Is Attention All You Need?
🌈 Abstract
The article discusses the progress and challenges in the field of Transformer architectures, as well as the emergence of alternative architectures that aim to outperform Transformers in areas where they struggle, such as long-context learning/generation and inference speed/cost. It explores the key ideas behind these alternative approaches, including linear RNNs, state-space models (SSMs), and hybrid models that combine sparse attention with RNN/SSM components. The article also covers architecture-agnostic improvements that could further enhance the performance of Transformer models, such as distributed computing, faster attention computation, and advancements in specialized hardware.
🙋 Q&A
[01] Progress in Transformers Towards Subquadratic Attention
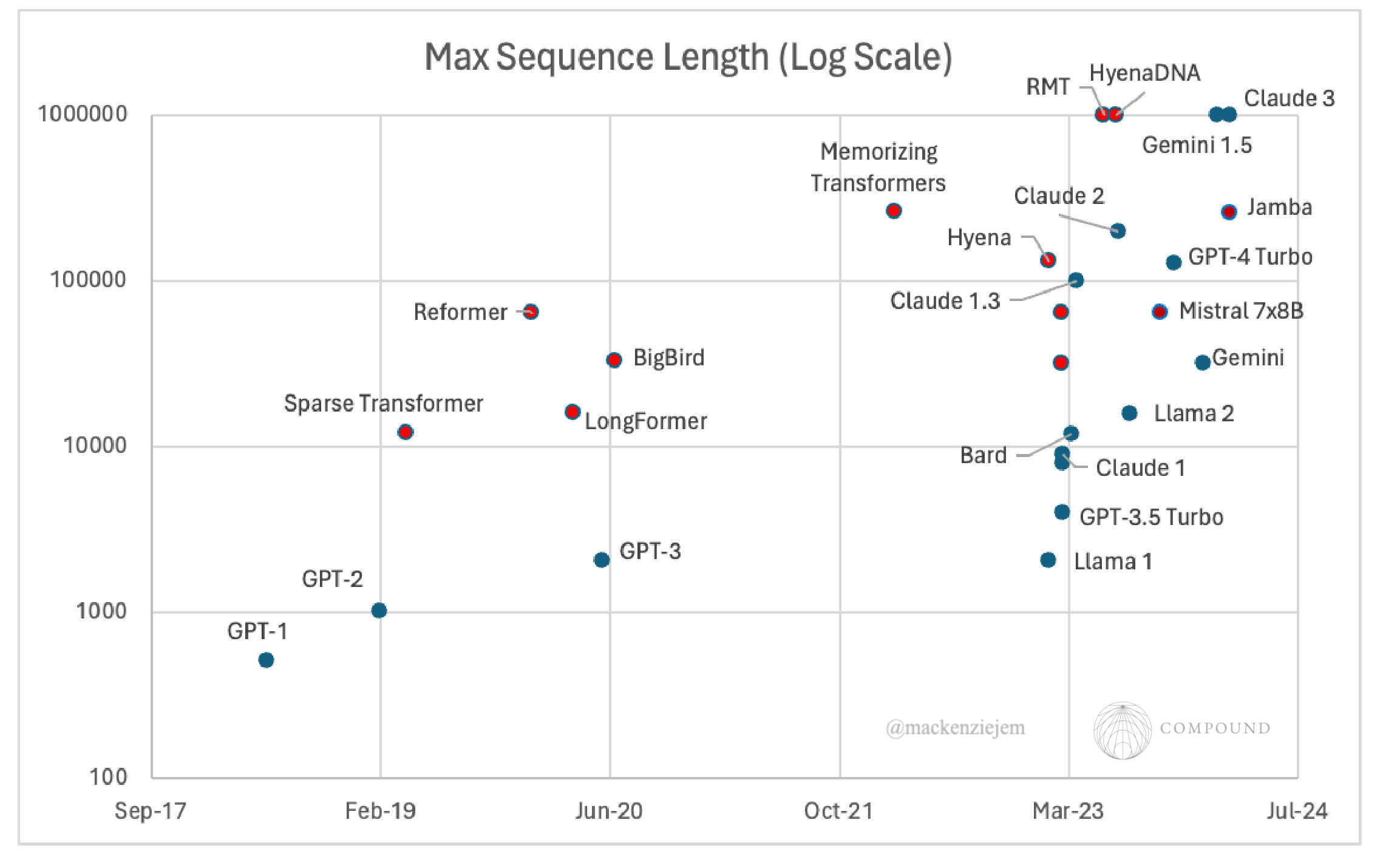
1. What is the key limitation of the vanilla Transformer architecture? The key limitation of the vanilla Transformer architecture is that it scales quadratically in sequence length (due to attention) and model dimension (due to MLP layers), which hurts its ability to model long sequences, speed during inference, and overall compute efficiency.
2. What is the intuition behind the idea of subquadratic attention? The intuition behind subquadratic attention is that in language modeling, a subset of words contributes most of the meaning, and there is locality to meaning, where a word contributes more to its neighbors than to those far away. This suggests that the attention mechanism can be made sparse, where each position only attends to a subset of the positions, in order to reduce the quadratic compute and memory burden.
3. What are the main approaches to achieving sparse attention? The main approaches to achieving sparse attention can be categorized as: (i) fixed and random, (ii) learned and adaptive, and (iii) identified with clustering and locality sensitive hashing.
4. Why haven't the sparse attention mechanisms been more widely deployed in top models compared to other conditional computing methods? The article suggests that despite the significant progress in sparse attention mechanisms, they have not been as widely deployed in top models compared to other conditional computing methods like sparse MoEs and quantization. The author notes that there is a "graveyard of ideas around attention", implying that the deployment of these mechanisms has faced challenges.
[02] Potentially Transformative Alternative Architectures
1. How do RNNs and SSMs differ from Transformers in their approach to modeling the past? Whereas Transformers seek to store all mappings of the past in memory and are thus limited by an ever-growing memory burden, RNNs and SSMs seek to distill the past into a fixed state size and are thus limited by their ability to do so with minimal functional loss.
2. What are the key mechanisms that enable modern linear RNNs and SSMs to achieve impressive performance? The key mechanisms include: 1) High-order polynomial projection operators (HiPPO) to memorize signals' history, 2) diagonal plus low-rank parameterization of the HiPPO, and 3) efficient kernel computation of an SSM's transition matrices in the frequency domain.
3. What is the importance of data-dependent gating and hybrid architectures in the alternative models? Data-dependent gating is seen as a crucial ingredient for effective linear-complexity alternatives to softmax attention, as it allows the model to selectively remember important information. Additionally, the combination of complementary mechanisms, such as sparse attention and RNN/SSM blocks, appears to be most effective, as it retains the accuracy of dense attention on local context with the throughput and long-context modeling of the alternative approaches.
4. Why haven't the alternative architectures been scaled beyond 200M-14B active parameters, despite their competitive performance? The article suggests that one possible explanation is that the Transformer architecture has been relatively static since its conception, with the ecosystem and resources focused on scaling and deploying it. In contrast, the Cambrian explosion of alternative architectures has led to the invention of new models on a monthly basis, and companies may be waiting for a clear champion to emerge before investing in scaling these alternatives.
[03] Architecture-Agnostic Improvements Likely Favor Transformers
1. How can distributed computing techniques like ring attention help address the memory limitations of individual GPUs/TPUs for Transformer models? Distributed computing techniques like ring attention can enable attention computation across the full sequence without requiring the entire memory to be present on a single device. This allows the input sequence to be split and distributed across multiple devices, enabling sequence training and inference size to scale linearly with the number of GPUs without making approximations to attention or additional overhead computation.
2. How can algorithms like FlashAttention improve the compute efficiency of attention in Transformer models? FlashAttention uses techniques like tiling and recomputation to restructure how GPUs compute attention, minimizing reads and writes to high-bandwidth memory (HBM) and shifting the bottleneck from memory to FLOPs. This can result in a 2-4x speedup in attention computation compared to standard attention.
3. How can advancements in specialized hardware, such as photonic computing and increased GPU memory, benefit Transformer models? Photonic computing with optical interconnects can enable GPUs to communicate at the speed of light, improving the effectiveness of distributed computing approaches like ring attention. Additionally, the continued increase in GPU memory size may favor fixed-state models like RNNs and SSMs, as they can store larger internal states without as much need for distillation.
4. Why do the architecture-agnostic improvements discussed in this section likely favor Transformers over the alternative architectures? The article suggests that as long as Transformer alternatives take to decisively outperform Transformers, the less likely it will be to happen, due to developer and enterprise lock-in with Transformers. The architecture-agnostic improvements discussed, such as distributed computing, faster attention computation, and hardware advancements, can disproportionately benefit Transformers and maintain their dominance as the universal architecture.