Pop Song Generators, 3D Mesh Generators, Real-World Benchmarks, and more
🌈 Abstract
The article discusses the growing need for faster and higher volumes of inference for large language models (LLMs), beyond just the need for more compute power for training. It highlights the work of companies like Groq and SambaNova that are enabling hundreds of tokens per second of generation, which can benefit agentic workflows and model evaluation. The article also discusses the rapid decline in training and inference costs, which will benefit application builders and help AI agentic workflows take off. Additionally, the article covers new text-to-song generation tools, industry-specific benchmarks for large language models, and a method for generating 3D models from single 2D images using video diffusion.
🙋 Q&A
[01] Importance of Faster Inference for LLMs
1. What are the key reasons why faster inference for LLMs is important, beyond just the need for more compute power for training?
- In an agentic workflow, an LLM might be prompted repeatedly to reflect on and improve its output, use tools, plan and execute sequences of steps, or implement multiple agents that collaborate with each other. This can generate hundreds of thousands of tokens or more before showing any output to a user, making fast token generation very desirable and slower generation a bottleneck.
- Faster, cheaper token generation will also help make running evaluations (evals) more palatable, as evals typically involve iterating over many examples, which can be slow and expensive today. Better evals will help many developers with the process of tuning models to improve their performance.
2. What are some examples of companies working on enabling faster inference for LLMs?
- Groq can generate hundreds of tokens per second.
- SambaNova recently published an impressive demo that hit hundreds of tokens per second.
[02] Declining Costs of Training and Inference
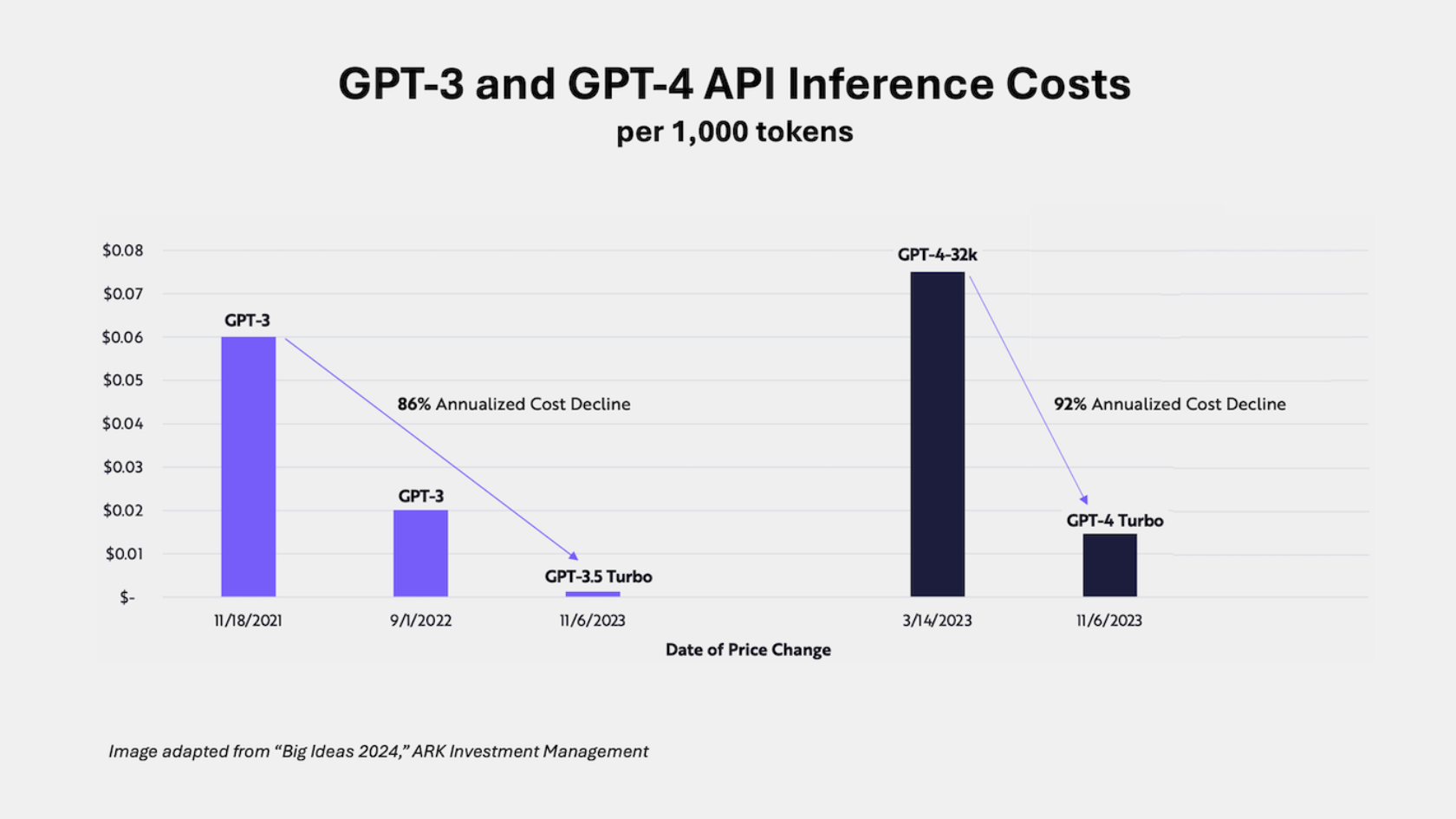
1. What are the estimates for the rate of decline in AI training and inference costs?
- According to Cathie Wood and Charles Roberts of ARK Investment, AI training costs are falling at 75% per year.
- They also report that for "enterprise scale use cases, inference costs seem to be falling at an annual rate of ~86%, even faster than training costs."
2. How will the rapid decline in training and inference costs benefit the development of AI applications?
- The declining costs will be good for application builders and help AI agentic workflows lift off.
[03] Text-to-Song Generation
1. What are the key capabilities of the new text-to-song generation tools from Udio and Suno?
- Both services can generate full-band productions complete with lyrics, vocals, and instrumental solos, based on text prompts.
- Users can generate lyrics to order or upload their own words, and they can download, share, and/or post the results for others to hear.
- Udio generates audio segments 33 seconds long, which users can extend, remix, and modify.
- Suno generates complete songs up to 2 minutes long.
2. What are some of the limitations of the current text-to-music models?
- They offer little ability to steer their output and don't respond consistently to basic musical terminology such as "tempo" and "harmony."
- Requesting a generic style like "pop" can summon a variety of subgenres from the last 50 years of popular music.
[04] Industry-Specific Benchmarks for LLMs
1. What are the key industry domains covered by the benchmarks developed by Vals.AI?
- The benchmarks cover tasks associated with income taxes, corporate finance, and contract law, in addition to a pre-existing legal benchmark.
2. How did the top-performing LLMs, GPT-4 and Claude 3 Opus, perform on these industry-specific benchmarks?
- GPT-4 topped the CorpFin and TaxEval benchmarks, correctly answering 64.8% and 54.5% of the questions, respectively.
- Claude 3 Opus narrowly beat GPT-4 on the ContractLaw and LegalBench benchmarks, achieving 74.0% and 77.7% accuracy, respectively.
[05] Generating 3D Models from Single 2D Images
1. What is the key insight behind the method developed by the Stability AI researchers for generating 3D models from single 2D images?
- The approach leverages a video diffusion model to generate an orbital video from a single image, and then uses the information in the orbital video frames to train a NeRF (Neural Radiance Field) model to produce a 3D model of the object.
2. How does the method improve upon the 3D model generated by the NeRF model?
- The authors further refine the 3D model using a diffusion-based approach, where they render images of the 3D model along random camera orbits, add noise to the image representations, and then use the video diffusion model to remove the noise, helping the 3D model to better match the original object.