Grokking gradients in deep neural networks
🌈 Abstract
The article discusses the factors that influence the gradients of the weights in a deep neural network, which can help understand why some networks are slow to converge. It provides an intuitive explanation of how different factors in the network affect the computation of gradients at each layer, followed by a detailed mathematical derivation.
🙋 Q&A
[01] Gradients and Computation Graphs
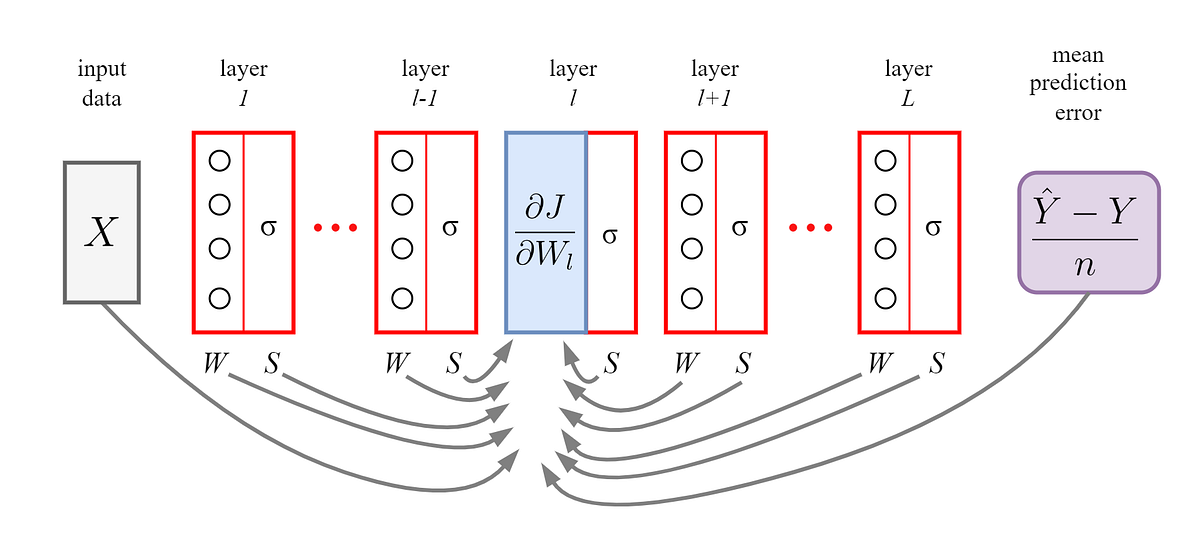
1. What factors influence the gradients of the weights at any layer in a deep neural network? The gradients of the weights at any layer are influenced by:
- The input training data (X)
- The mean prediction error (Ŷ - Y)
- The weights of all other layers (except the target layer)
2. How do these factors linearly affect the gradients across the depth of the network?
- The input training data (X) has an equal and linear effect on the gradients of all layers.
- The mean prediction error (Ŷ - Y) also has an equal and linear effect on the gradients of all layers.
- The weights of other layers have an approximately equal effect on the gradients of all layers, except for the target layer.
3. How does the inclusion of activation functions affect the intuitive gradient equation?
- The activation functions are represented by diagonal matrices (S) that capture the non-linearities.
- Each S matrix attenuates the effect of the corresponding weight matrix (W) on the gradients.
- The combined effect of W and S splits the computations into a linear component (W) and a non-linear adjustment component (S).
[02] Intuitive Effect of Inactive Units
1. How do inactive units (where the activation function output is zero) affect the gradients in the network?
- For the layer with the inactive unit, the entire corresponding column of weight gradients becomes zero.
- The remaining gradients in that layer are attenuated to 2/3 of what they would have been if all units were active.
- The gradients in the very next layer get the same treatment but transposed, and all other layers are attenuated to 4/9 = 0.4444 of what they would have been.
- This suggests that sparsely activated networks (where most units tend to be inactive) will tend to learn slower than others.
[03] Intuitive Effect of Biases
1. How do the biases affect the gradient computations?
- Only the biases in the layers before the target layer have any effect on the gradients of the weights at that layer.
- The calculation of the gradients of the biases only includes the layers after the target layer, proceeding from the last layer towards the target layer.
[04] Vanishing and Exploding Gradients
1. How do the weights and activation rates contribute to the vanishing and exploding gradient problems?
- If the mean weight of each layer is less than 1.0, the net effect after L layers is w^L, which can lead to vanishing gradients.
- The activation function's attenuation effect (captured by the S matrices) compounds this problem, as the mean weight * activation rate should be close to 1.0 to maintain good gradient propagation.
- Exploding gradients are less frequent than vanishing gradients, leading to very slow learning.
[05] Detailed Computation Graph
1. How is the backpropagation algorithm represented in the detailed computation graph?
- The forward pass is represented by the green boxes, where the input data X is transformed through the weight matrices and activation functions.
- The backpropagation algorithm is represented by the purple boxes, which compute the gradients by propagating the mean prediction error (Ŷ - Y) backwards through the network.
- The backpropagation algorithm uses the chain rule to compute the partial derivatives at each layer, leveraging the cached values from the forward pass.
2. How are the gradients of the weights and biases computed from the detailed computation graph?
- The gradients of the weights are computed by multiplying the transposed input activation of the layer with the propagated gradients.
- The gradients of the biases are computed by summing the propagated gradients along the sample dimension.
[06] Effect of Different Loss Functions
1. How do different loss functions (MSE, cross-entropy) affect the gradient computation?
- For the common configurations of output activation function and loss function (e.g., sigmoid/softmax with cross-entropy), the gradient of the loss with respect to the network output takes a simple linear form: (Ŷ - Y).
- This linear form of the gradient is one of the factors that made deep learning possible, as it avoids the issues of vanishing or exploding gradients that can occur with other loss function formulations.
</output_format>